
Инфраструктура как код: лучшие практики для DevOps-инженеров
Infrastructure as a Code
Сегодня мы поговорим о практиках, которые используются в IAAC (Infrastructure as a Code). Часть из них для кого-то известна, а часть может стать новинкой. В любом случае эта статья будет полезной как для DevOps-инженеров, которые уже на собственном опыте знают, насколько важно покрывать инфраструктуру кодом, так и начинающим, которые только начинают свою работу с Terraform.
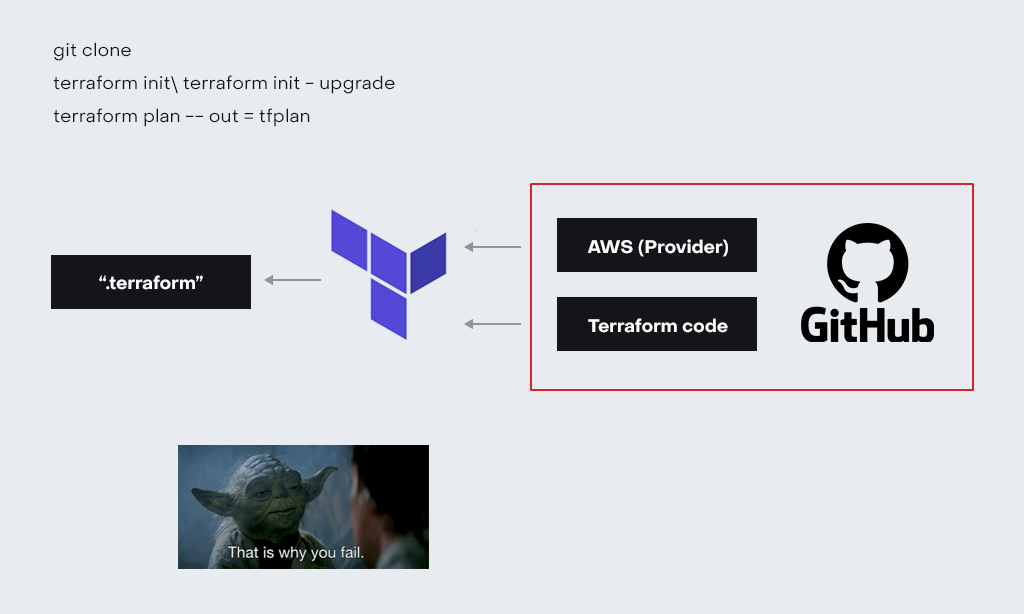
Начинать работу над проектом надо с инициализации, команда teraform init, которая загрузит все необходимые провайдеры, которые в свою очередь позволят работать с различными платформами (AWS, GCP, Azure, Cloudflare…).
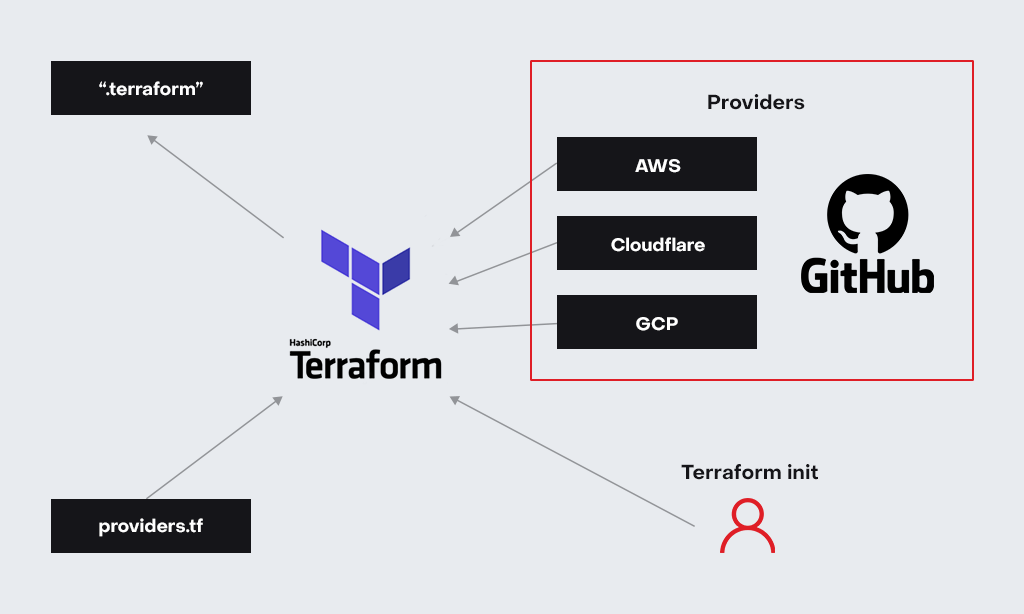
Провайдер — это в определенной степени инструкция, согласно которой Terraform понимает, как взаимодействовать с той или иной платформой.
Основные команды для работы с Terraform следующие:
- terraform init (проводит инициализацию проекта и загружает провайдеры, которые необходимы для деплоя в той или иной среде (смотри схему выше);
- terraform plan (позволяет увидеть, какие именно ресурсы terraform хочет создать или изменить или удалить);
- terraform apply\destroy (позволяет задеплоить\ удалить ресурсы, которые вы увидели на этапе terraform plan).
Удобство Terraform заключается в том, что над проектом может работать вся команда. Он поддерживает lock-механизм. Схему работы lock-механизма мы рассмотрим в статье далее.
Используйте удаленные state files и lock-механизм
Для сохранения изменений следует использовать удаленный state file, в котором есть текущее состояние инфраструктуры. Terraform также поддерживает локальный state-файл, но в этом случае вы не сможете работать командой над одним terraform-проектом, потому что ваши тиммейты не будут в курсе того, что делаете вы, а вы не будете в курсе того, что делают они. Также это грозит перезаписью или удалением ресурсов друг друга. То есть при первом запуске команды terraform plan мы создаем remote state file (предварительно указав путь в terraform), который отображает текущее состояние инфраструктуры.
Если в проекте работают два и более человека, один из которых проводит Teraform plan\apply, то другой в этот же момент, если попытается сделать одну из указанных команд, — получит уведомление о том, что его тиммейт уже работает с этим проектом, и надо немного подождать, пока закончится деплой\план и lock будет снят. Lock-механизм позволяет предотвратить перетирание ресурсов друг друга. Подробнее узнать о lock-mechanism можно по ссылке.
Иногда бывает так, что вы начали делать terraform plan\apply и у вас возникли проблемы с интернетом. В такой ситуации state file остается заблокированным, поскольку terraform plan\apply не завершился успешно, и state file не разблокировался. Инфраструктура как код. Для разблокировки state file используется команда terraform force-unlock <lock-id>, если именно вы заблокировали state file. Если это сделали не вы — дождитесь завершения deploy, если state file остается залоченным долгое время — спросите у тиммейта, можете ли вы сделать unlock state file (в terraform-сообщении будет видно, кто залочил state file).
Разделяйте terraform-файлы, основываясь на логическом распределении ресурсов:
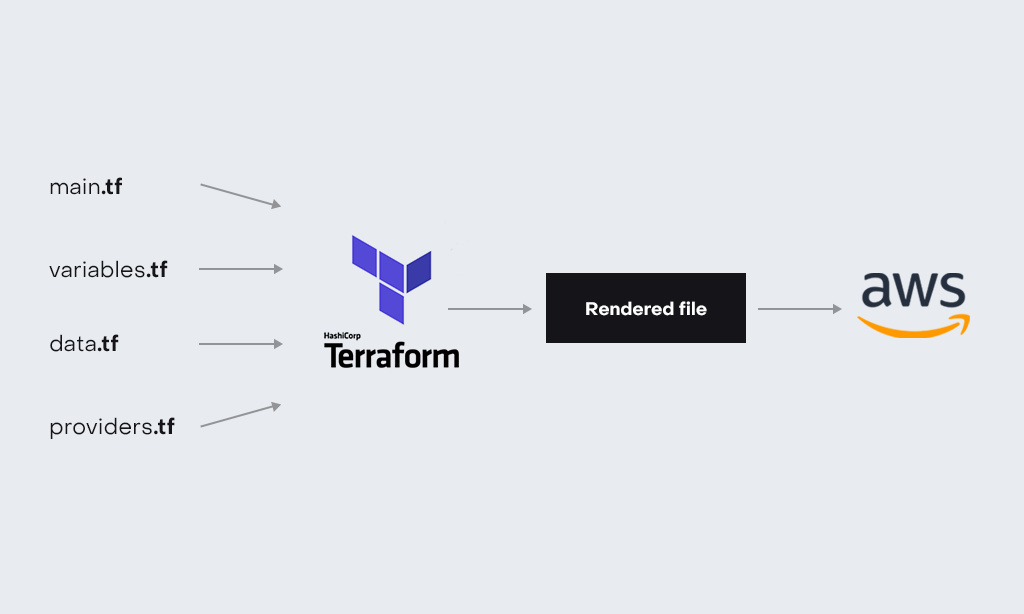
Все переменные соберите в один variables.tf файл, провайдеры — в providers.tf файл, data-ресурсы — в data.tf файл, и используйте их в main.tf файле. Благодаря этому тиммейты смогут легко разобраться в terraform-коде, потому что все будут on the same page и быстро поймут, где нужно изменить код для изменения инфраструктуры в том или ином направлении.
Terraform не требует логического распределения файлов. Что 20 файлов с расширением .tf, а что 1 файл с расширением .tf с тысячей строк кода — на этапе terraform plan все собирается в единый файл, который позже используется для деплоя. Значительно легче пересмотреть 10 файлов по 15 строк, чем один файл со 150 строками, поэтому я советую разделять файлы.
Используйте переменные вместо хардкода
Если значение используется в коде более одного раза, имеет смысл использовать переменные. В таком случае вы управляете только одним местом, где вы указываете переменную.
Представим ситуацию, где мы захардкодили определенное значение в тысячи строк кода. Если необходимо изменить значение, нужно переписать его во всех местах, где мы его захардкодили. Чтобы избежать этого долгого процесса, можем указать это значение один раз в variables .tf файле — вместо хардкода использовать переменную — и вуаля. Добавив переменную в одном месте variables.tf файла, мы изменим ее в тысячах мест.
Мой совет — объединять variable в логические цепочки. Например, если есть три переменные: vpc_id, vpc_cidr, subnet_group, давайте объединим их в одну объектную переменную network, которая в свою очередь будет иметь три атрибута (vpc_id, vpc_cidr, subnet_group). Для чего нам это нужно? Во время деплоя terraform мы используем API calls под капотом. Каждый отдельный API call — это определенное время, которое тратим на обработку. Чем больше API calls — тем больше времени на terraform plan\deploy. И все, вроде бы, хорошо, если речь идет о деплое одного инстанса в облако. Мы не заметим большой разницы — у нас одна переменная с тремя атрибутами или три разные переменные. Представим, что в проекте 1000 ресурсов, время на plan и apply terraform возрастает, если вместо одной object переменной мы будем использовать три отдельные. Да и в коде это выглядит лучше, когда мы объединяем переменные в логические объекты.
Таким образом мы разгружаем работу с Terraform и уменьшаем время отклика. К объектной переменной мы можем обратиться следующим образом: var.network.vpc_id, var.network.vpc_cidr, var.network.subnet_group.
Нейминг variable — важный момент в работе. Особенно это ощутимо, если вы написали код, с которым будет работать вся команда. Потратьте 5 минут на название переменной, в будущем это может сохранить час времени для команды.
Используйте модули
Модуль — это логическое объединение ресурсов, которые могут использоваться в разных проектах. Обычно ресурсы модуля идентичны для разных проектов, отличаются только значения переменных.
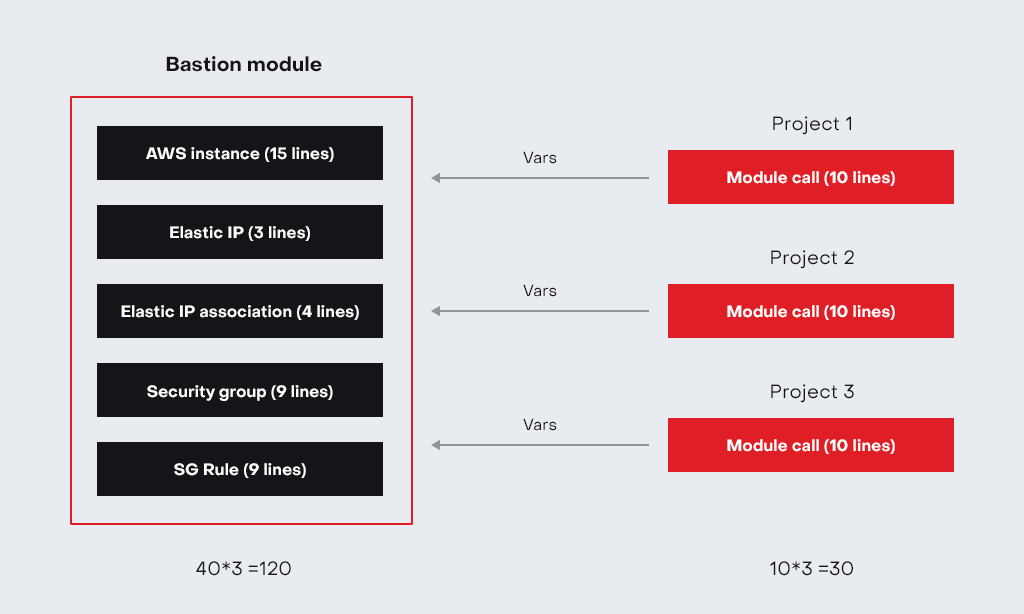
Используя модули, мы избегаем дублирования кода. Если нам нужно создать 15 одинаковых инстансов (требующих security_group, security_group_rules, public_ip etc.) в разных проектах, можем написать один модуль и 15 раз его вызвать. Вместо 400 строк кода получим только 15. Таким образом мы создадим 15 различных ресурсов, но с помощью одного модуля.
Благодаря модульности код легче управлять. Представим, что мы создали bastion module, который используется в 15 проектах. Открылся, к примеру, новый офис в компании, и нам необходимо добавить еще один IP-адрес в bastion security_group. Если бы у нас не было модуля, нам нужно было бы добавить новый IP-адрес к каждому бастиону в 15 проектах. Каждое изменение, которое мы делаем вручную в коде, может стать потенциальной ошибкой в силу человеческого фактора. Но мы используем модуль, поэтому достаточно будет добавить новый IP-адрес в одном месте (это поможет избежать человеческого фактора, о котором упоминали ранее и уменьшить время на корректировку переменной в одном месте вместо 15), сделать деплой кода и все. Таковы преимущества модульности.
Используйте ‘count’ function для создания одинаковых ресурсов или для решения ‘if case’ для ресурса
Функция ‘count’ может помочь нам в создании как одинаковых ресурсов с разными именами, так и решить ‘if condition’ внутри ресурса.
Назначение count функции вы можете посмотреть в официальной документации terraform, ниже — я хотел бы рассказать, как функция ‘count’ может помочь сделать наш модуль более гибким или ресурс, который требует if condition на основе тех или иных данных. Например, есть два DNS-провайдера — это Cloudflare и Route53 в Amazon. Разные системы используют разные провайдеры. Но у нас есть модуль, который создает вебсервер, и сопроводительные ресурсы инстанса (security group, security_group_rule, public_ip и другие).
Если не использовать функцию count с if condition, нам необходимо просто задублировать код и создать два модуля. В первом случае это будет модуль с Cloudflare записью, во втором — модуль с Route53 записью. Но дублировать весь модуль, в котором 500 строк общего кода и только 10 строк, которые отличаются, — это не лучшая практика.
Чтобы решить эту ситуацию, мы как раз и можем использовать функцию count по назначению. Таким образом при вызове модуля указываем, что провайдер равен Cloudflare. Если да, то функция вернет нам единицу и таким образом создастся Cloudflare-запись в Cloudflare. Далее мы заходим в следующий ресурс Route53 и так же благодаря count проверяем. Соответственно условие будет 0, и мы не будем создавать запись в Route53. Если мы укажем провайдер Route53, то все произойдет наоборот, в отличие от первой ситуации, создастся Route53 dns запись, а Cloudflare не будет. Это очень важная опция внутри Terraform, которая помогает сделать модуль гибким.

Data resources существующих ресурсов
Представим ситуацию, что terraform создает новый ресурс, и появляется необходимость в определенном атрибуте ресурса, который вы создали вручную. Например, вы хотите создать security_group inbound rule для уже существующего инстанса.
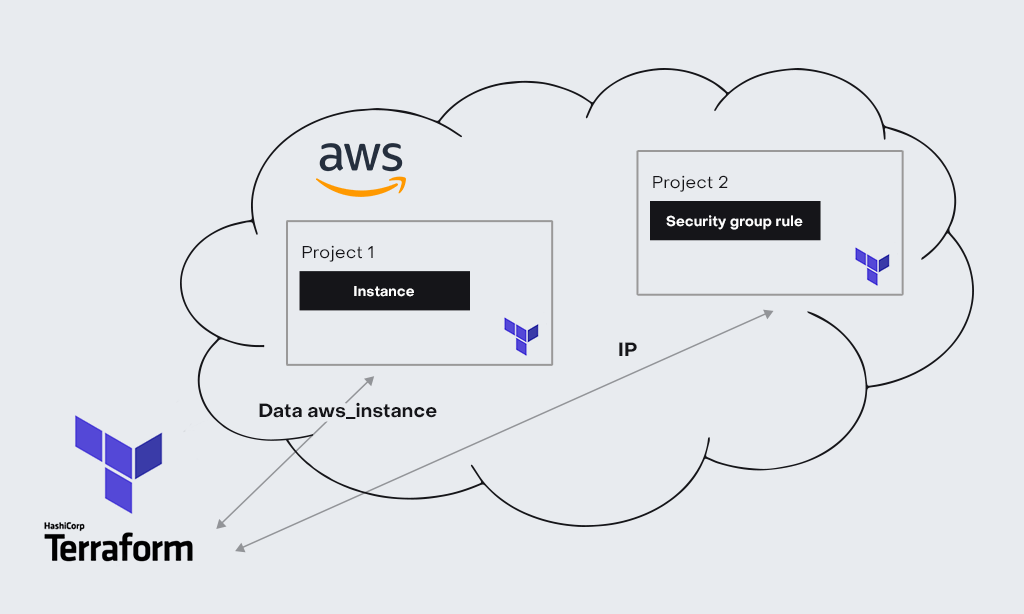
Для этого вам необходим IP-адрес инстанса. У вас есть несколько вариантов, как это сделать:
- Захардкодить (это не лучшая практика, и я не рекомендую ее, но такой вариант все еще существует).
- Использовать data_resource, который позволит вам получить IP-адрес инстанса (это лучшая практика, которую я рекомендую).
Почему хардкод — это плохо, а использование data_resource — это хорошо? Представим ситуацию, что по какой-то причине IP-адрес инстанса изменен. Если мы используем data_resource, то при каждом запуске terraform plan информация об инстансе обновляется, и terraform предлагает заменить старый IP на новый. Если же мы используем хардкод, тогда terraform ничего об этом не будет знать, пока вы не внесете изменения в код. А если у вас таких изменений 100 на проекте, это добавит работы и займет много времени. Чтобы использовать data_resource, нужно указать ID ресурса, атрибут которого вы хотите получить. Для каждого ресурса ID отличается, проверяйте terraform документацию. Этот подход действенный в случае, если часть инфраструктуры еще не описана кодом, а часть — в процессе покрытия.
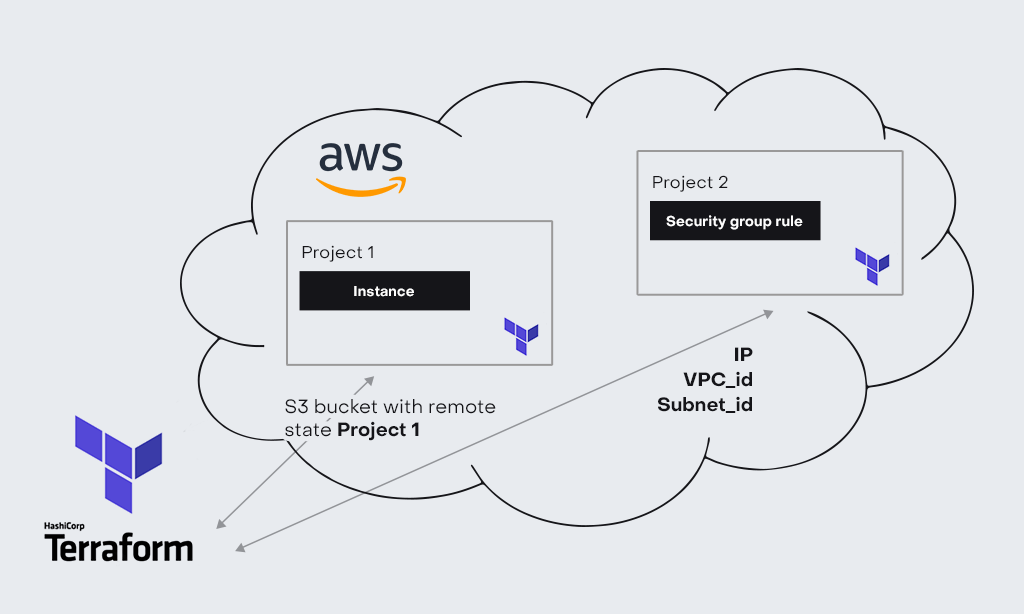
Если же инфраструктура уже описана кодом, то вместо того, чтобы делать API-call в AWS (data_resource), мы можем использовать data resource к state file (terraform_remote_state), который хранится в s3 bucket. Для этого делаем запрос и получаем все ресурсы для создания текущей инфраструктуры.
Подытоживая сказанное, у нас есть два варианта:
1) более сложный путь, когда мы делаем 15 API-calls в AWS, собираем всю необходимую информацию и таким образом продолжаем создавать инфраструктуру (это рабочий вариант в ситуации, когда мы хотим получить определенные атрибуты ресурсов, которые еще не покрыты terraform);
2) более простой и удобный — делаем один API-call в s3 bucket и получаем эти 15 ресурсов (terraform_remote_state), которые нам необходимы (инфраструктура, покрытая terraform). В этом случае важно понимать, что в state file проекта, к которому мы обращаемся, должны быть outputs для атрибутов, которые нам необходимы. Таким образом мы опять же разгружаем Terraform flow, спокойно увеличивая производительность и уменьшая время отклика. Соответственно, если у нас 700 таких ресурсов (data_resource), то время на их получение умножается. Если же мы используем data_remote_state, и у нас есть все 700 outputs, в таком случае вместо 700 API-call — мы делаем один.
Подытоживая, если у вас есть возможность использовать remote_state_file из другого проекта — используйте и разгружайте terraform. Если нет — используйте data_resource, но не хардкодите значения.
Если используете инфраструктуру кода — не делайте изменения вручную, но даже если так произошло — отметьте это в terraform
Никаких ручных изменений, если уже начали использовать Infrastructure as a Code.
Часто случается так, что terraform помогает вернуть инфраструктуру в рабочее состояние. Представим ситуацию, что кто-то случайно допустил ошибку, и ваш сайт не открывается. Чтобы понять, почему так произошло, нужно провести дебаггинг, который занимает время. Вместо этого вы можете сделать terraform plan, и он уже покажет вам, какие изменения были сделаны до этого. В таком случае terraform applу решит вашу проблему за несколько минут.
Но когда упал продакшн, и terraform plan\apply не вернул инфраструктуру в рабочее состояние — не тратьте время на исправление terraform кода, сначала решите проблему вручную, позже все укажите в terraform в спокойном режиме. Это уменьшит время вашего даунтайма, что в свою очередь уменьшит количество потерь. Если же изменения не связаны с production issue, то все необходимо делать через Terraform код.
Когда изменения вносятся вручную, то ситуация выглядит так: один сделал изменения в тегах в инстансах, другой — изменил data base retention period до 4 или 8 дней. Когда мы сталкиваемся с production issue, то вместо одного изменения, которое является root cause — мы увидим, что terraform хочет сделать 4 изменения в разных местах. В таком случае вместо одного ресурса вам надо пересмотреть 4, а на это все уйдет время. А если вы меняли не 4 ресурса, а 20, то это еще больше времени. Конечно, с ручными изменениями надо бороться. Хотя и я в своей работе с этим сталкиваюсь, и это отнимает мое время и время моих коллег. Поэтому целесообразнее инфраструктуру покрывать кодом и все прописывать в Terraform.
Используйте import resources, если проект не является частью terraform, а вы хотели бы покрыть его кодом
Если ваш проект полностью покрыт terraform или же определенная его часть — это очень хорошо. Но есть ситуации когда ресурсы частично созданы terraform, а частично — вручную. Если нам необходимо покрыть все ресурсы terraform — в этом случае поможет terraform import команда. В Terraform есть детальное описание, как делать импорт тех или иных ресурсов. Terraform проводит команду import, и таким образом забирает на себя менеджмент инфраструктуры. Алгоритм импорта следующий:
- Написать terraform код для ресурса, который будете импортировать.
- Выполните команду terraform plan (команда должна показать вам, что ресурс, который вы хотите импортировать, создастся).
- Импортируйте ресурс с помощью команды terraform import resource_id (для каждого ресурса resource_id отличается, проверьте документацию terraform).
- Снова сделайте terraform plan команду (если импорт сделали корректно, terraform должен показать сообщение: ‘The infrastructure is up to date’).
В процессе покрытия инфраструктуры кодом вы шаг за шагом имплементируете terraform. Соответственно в следующий раз все изменения можно вносить с помощью Terraform, а не руками.
Команду import можно использовать, когда у нас есть два или три проекта — Backend, Frontend и DevOps, которые уже покрыты terraform. Вчера это могло принадлежать Backend, а сегодня — DevOps. Поэтому нам надо сделать импорт из Backend в DevOps. В свою очередь мы должны удалить этот ресурс из Backend (terraform state remove), и таким образом мы можем и там, и там менеджировать Terraform. Очень важно, чтобы один ресурс менеджился только с помощью одного terraform state file, иначе будет постоянная перезапись. Представим ситуацию, что у вас ресурс меняется с помощью двух terraform state file DevOps и Backend, и в каждом проекте используются default_tags. Каждый раз при terraform apply будут записываться теги для DevOps-проекта и для BackEnd. Во избежание двойной работы сохраняем resourse только в одном Terraform state file.
Прежде чем работать с remote tf.state, нам надо предупредить об этом команду, чтобы никто не трогал state file, пока вы не завершили с ним работать.
После завершения работы с remote tf.state тоже необходимо сообщить, что вы завершили, и другие могут работать с файлом. Успешным завершением при импорте ресурсов является результат команды terraform plan «infrastructure is up to date».
Убедитесь, что не допустили ошибку в форматировании Terraform fmt и в синтаксисе Terraform validate
Когда мы пишем код Terraform, все это может иметь неструктурированную форму. Тогда можно воспользоваться командой terraform fmt -recursive и придать этому упорядоченный вид. Особенно это удобно, если у тебя 30 файлов, которые можно форматировать одновременно. Отследить это все глазами сложно, особенно если проект состоит из тысячи строк кода, а код всегда хочется видеть читабельным. Также удобной является команда terraform validate, которая при разработке terraform-кода позволяет проверить, хватает ли terraform всех атрибутов, чтобы выполнить terraform plan\apply.
Используйте версию провайдера только в корне проекта — тогда вам не придется менять его в разных местах
Как я уже отмечал в начале статьи, terraform использует провайдеры для работы с различными платформами. Провайдер — это драйвер (инструкция), который указывает terraform, как взаимодействовать с платформой. В одном terraform-проекте может быть несколько провайдеров. Представим ситуацию, что вам необходимо создать веб-сервер, который должен быть доступен по адресу example.terraform-learn.com.
Чтобы создать вебсервер, вы можете использовать AWS\GCP\Azure etc. облачные провайдеры. Для каждого облака написан свой провайдер. После создания сервера вам необходимо создать DNS-reсord, который будет направлять трафик на ваш вебсервер. Для создания DNS-ресорда в CloudFlare необходимо использовать Cloudflare Provider.
Если в вашем проекте есть много приложений, лучшая практика — декларировать версию провайдера в корне проекта.
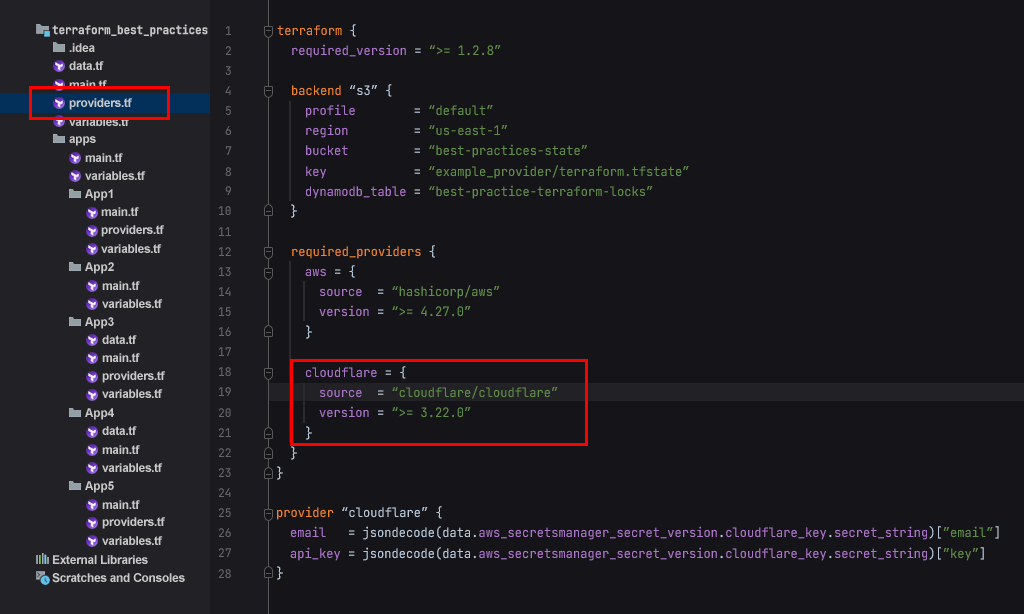
Далее – внутри каждого приложения, если необходим провайдер, вы ссылаетесь на корневую версию. Таким образом, вы меняете версию провайдера только в корне проекта.
Еще хочу добавить несколько слов, которые могут сэкономить вам время на поиск проблемы, с которой в свое время столкнулся я. Давайте представим ситуацию, что у вас есть terraform-проект. Вы с ним работаете на данный момент, и у вас все хорошо.
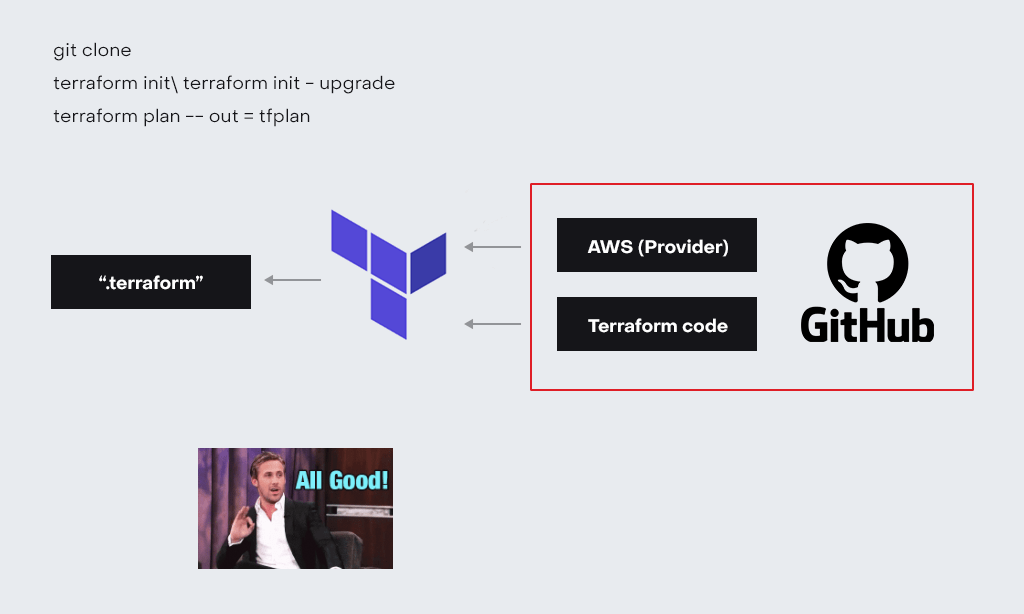
На следующий день вы выполняете те же команды:
- git clone;
- terraform init\terraform init -upgrade;
- terraform plan.
И у вас возникает ошибка. Сначала вы думаете, что проблема с вашим кодом, идете в GitHub, смотрите, а там нет никаких изменений со вчерашнего дня, когда у нас все работало. И тут возникает вопрос, что же такое произошло. Идете к коллегам, просите сделать terraform plan, и у них все получается. Что же это за магия? Вы продолжаете делать дебагинг и не понимаете, в чем дело.
Давайте теперь разложим все по полочкам и разберемся, в чем же заключается магия ошибки, если вы ничего не меняли. Спойлер — что-то таки было изменено, и это не магия.
- Действительно, код не менялся с момента, когда все работало корректно.
- Действительно, terraform plan работает на компьютере вашего коллеги.
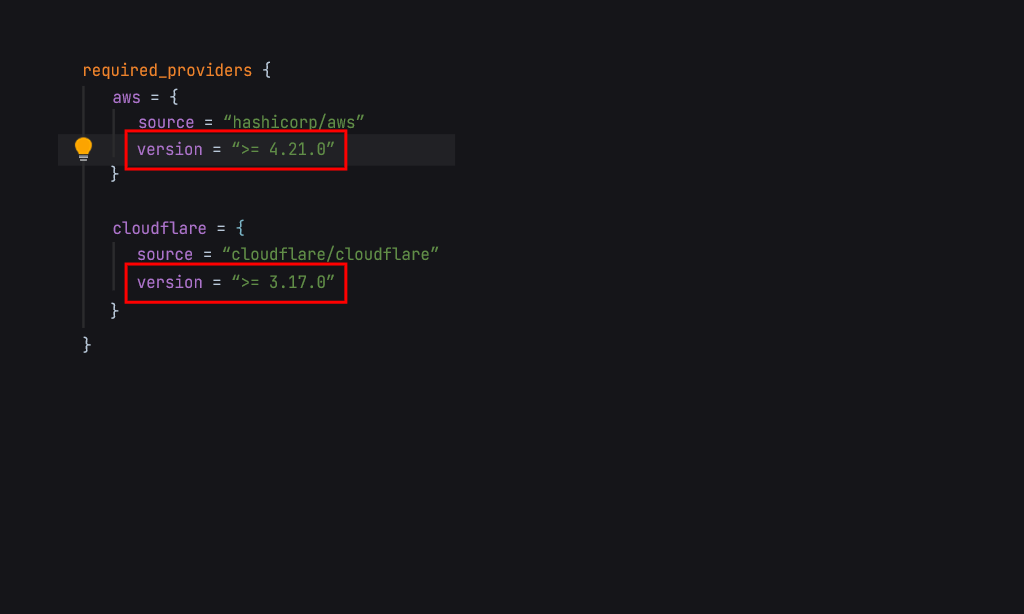
Все дело заключается в провайдере. С момента, когда у вас все работало и до того момента, когда перестало — версия провайдера (например, CloudFlare) изменена, и сегодня вы уже не можете сделать план на создание DNS-record. Хорошо, скажете вы, но почему это работает у вашего коллеги?
Это хороший вопрос. У вашего коллеги это работает, потому что не запустили команды terraform init\terraform init-upgrade, и ваш коллега использует не последнюю версию провайдера. Вы же в свою очередь клонировали свежий код и инициализировали terraform, который взял последний провайдер (вчера он был 4.21.0, сегодня он — 4.22.0), если, конечно, ваш провайдер не закреплен в terraform. Если ваш коллега сделает terraform init\terraform init -upgrade, у него также появится эта проблема.
Используйте default tags — тогда все ресурсы внутри проекта будут иметь default tags
Хорошая практика — использовать для ресурсов теги. В таком случае вы всегда будете знать, кому принадлежит ресурс и покрыт ли он terraform. Также когда вы просматриваете costs, по тегам легко определить, кого надо спрашивать, почему инфраструктура съела так много денег. Для покрытия ресурсов тегами есть два подхода:
- Добавлять теги к каждому ресурсу (это хорошая практика, но не лучшая).
- Использовать default_tags в корне проекта. Это лучшая практика. В этом случае все ресурсы, которые находятся внутри проекта будут иметь дефолтные теги. Если вам кроме дефолтных тегов, нужно добавить любые уникальные теги — используйте конструкцию merge. В этом случае даже если мы пропустим какой-то ресурс и не покроем его тегами — terraform его не пропустит и покроет.

На основе тегов можно сделать целую автоматизированную систему, которая будет с помощью скрипта выгребать по тегам состояние инстанса и прочее.
Делайте terraform plan с ключом -out=tfplan и только тогда применяйте
При создании или изменении инфраструктуры мы используем terraform plan команду. Эта команда показывает нам, что terraform собирается сделать в инфраструктуре. Если мы делаем terraform plan, terraform показывает нам, что будет сделано непосредственно в консоли. Если же мы используем ключ -out=tfplan, в таком случае terraform запишет все изменения, которые будут сделаны в локальном файле.
Мы можем делать terraform plan как с ключом, так и без него. Это будет работать одинаково. Разница лишь в том, что с использованием ключа будет создан локальный файл со всеми изменениями, которые будут сделаны, а если мы не будем использовать вышеупомянутый ключ, то все изменения будут показываться только в консоли. Если что-то пойдет не так — вы всегда можете открыть tfplan файлы и посмотреть, что планировалось сделать, а что фактически сделано.
Инфраструктура как код : подытоживая, скажу самое главное — инфраструктуру надо покрывать кодом. Придерживайтесь Clean Code Principles при написании кода. Избегайте дублирования кода — иногда значительно быстрее сделать Сору\Paste и забыть, но в таком случае будет расти количество вашего кода, а не качество. При разработке кода и сети в ‘main’ используйте PR Review, ведь, как правило, истина рождается в процессе дискуссии, и ваш коллега, который уже столкнулся с подобной ситуацией, может подсказать вам более оптимальный вариант.
Возможно будет интересно:
7 шагов к выбору правильных инструментов DevOps
Автор Игорь Канивец
# Инфраструктура как код











 на 100 слоях")






