Что следует знать об организации работы при переходе на микросервисную архитектуру.
Все началось с приложения, написанного на .NET Framework. В качестве облачной платформы мы выбрали Azure, как базу данных использовали Azure SQL, а системой контроля версий выступал Bitbucket. В качестве хостинга для API отдали предпочтение Azure App Services. Back-end хостился в виде Azure Cloud Service workers, которые были тесно связаны между собой и являлись монолитом. Разработка back-end велась в одном репозитории командой из 5 человек. Задачей команды было максимально быстро доставить изменения в production и получить обратную связь от пользователей.
Спустя полгода после начала работы количество пользователей выросло до 50 тысяч. Для его увеличения приняли решение расширить функциональность приложения. Число разработчиков увеличилось до 15, и они были разделены на несколько команд. Как методологию разработки мы использовали Feature driven development, фокус разработчиков был сосредоточен на функциональных элементах (features), полезных с точки зрения пользователя. Владение кодовой базой на данном этапе было коллективным (collective code ownership), ответственность команд заключалась в имплементации новой функциональности, а также доставке изменений в production.
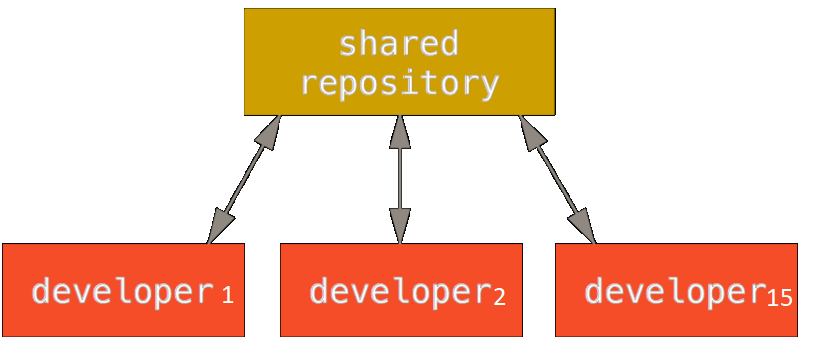
Коллективное владение кодовой базой, рост количества разработчиков и фокус на скорости релизов приводили к тому, что время на интеграцию кода (слияние изменений) и прохождение регрессионного тестирования увеличивалось.
Каждая из команд имела в своем владении dev environment, которая была максимально похожа на prod. Разработка новой функциональности (feature) для команды из 3–4 человек в среднем занимала 2–3 недели. Но за счет того, что количество QA-инженеров было ограничено, формировалась очередь на прохождение регрессионного тестирования на UAT, и в некоторых случаях это могла быть неделя или даже больше. Эти факторы вместе с ограничениями масштабируемости монолитного приложения в дни рассылки маркетинговых кампаний и постоянно растущая клиентская база дали толчок к переходу на микросервисную архитектуру.
На пути к изменениям: от монолита к микросервисам
Мы начали всю функциональность максимально переносить из монолитного приложения во вспомогательные или независимые микросервисы. В качестве инфраструктурной платформы был выбран Azure Service Fabric, так как она позволяет быстро настроить кластер и управлять масштабированием. Также Azure Service Fabric предоставляет богатую программную модель в виде stateful/stateless-сервисов, поддержку actor model и reliable state, которые мы использовали в своих микросервисах.
При разделении монолита мы применяли DDD, шаблон Decompose by Subdomain. Количество микросервисов увеличивалось с добавлением в продукт новой функциональности. Каждому микросервису мы выделили свою кодовую базу (репозиторий). При проектировании применялся подход отдельных баз данных (БД) под каждый микросервис. Для разделения ответственности в своем продукте мы использовали CQRS- и Event Sourcing-подходы, shared libraries поставлялись через NuGet.
Также был настроен процесс CI/CD с помощью TeamCity & Octopus. Микросервисы доставлялись в production в виде гранулярных rolling upgrade-деплоев.
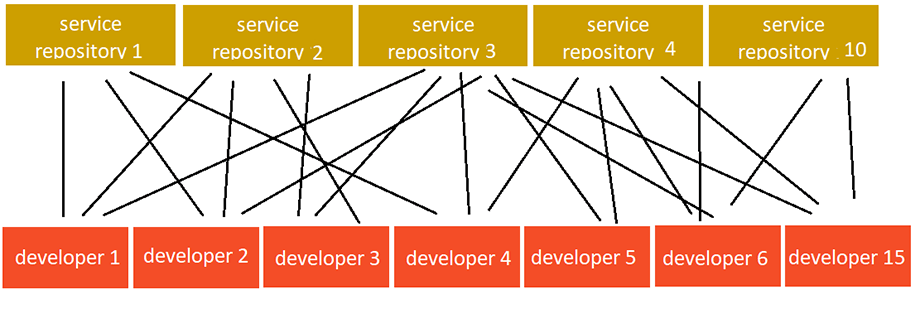
Распределенная кодовая база исключила все проблемы слияния. Команды больше фокусировались на процессе разработки и в то же время меньше беспокоились о продолжительном регрессионном тестировании. Затраты, выделяемые на масштабирование монолитного приложения, стали существенно ниже. Независимые микросервисы теперь масштабировались по необходимости, и мы могли выдержать нагрузку в 10 раз больше. Это позволило выдерживать пиковые нагрузки при запуске маркетинговых кампаний. Такие действия вместе с маркетинговой стратегией помогли увеличить клиентскую базу до 2 миллионов пользователей.
При разделении на микросервисы особое внимание уделяли безопасности.
Мы смогли реализовать ограничение по доступности своих сервисов на уровне подсетей (Network Security Groups, Demilitarized Zone). Некоторые компоненты, которые владеют информацией security sensitive, вынесены в изолированные кластеры. Вследствие кластеризации мы ежегодно проходим PCI DSS-сертификацию.
Введение strong code ownership и распределение ответственности
Вернемся к организационному аспекту. При разработке новой функциональности каждая из команд могла вносить изменения в любой микросервис и была обязана знать их устройство. В момент, когда общее количество микросервисов превысило 20, возникли трудности с процессом интеграции новичков в команду и обменом знаниями.
Решением стало введение строгого типа владения кодовой базой (strong code ownership) и разделение зон ответственности. Каждый сервис должен был принадлежать только одной команде, которая отвечает за внесение изменений, будущее развитие этого сервиса, его поддержку и доставку в production.
Воплощением strong code ownership в Wirex стали доменные команды, которые появились вместо feature teams. Команды были созданы вокруг доменов — областей знаний, логически объединенных бизнес-процессов и нашего приложения. Их сфера ответственности касалась нескольких микросервисов. Таких команд у нас пять, каждая из них управляет своими микросервисами.
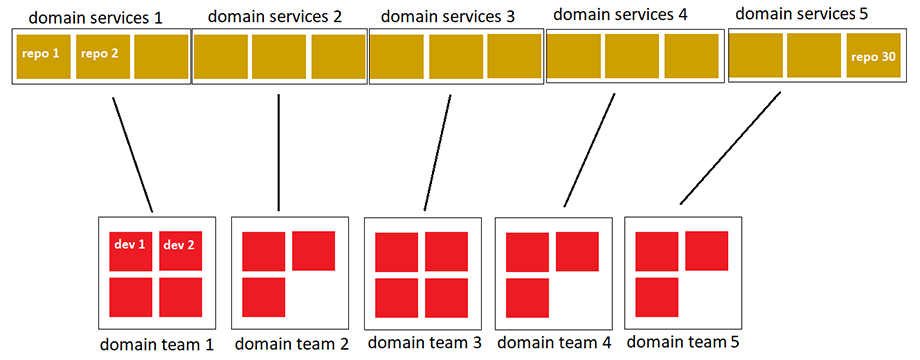
Сейчас у каждой доменной команды есть своя development environment, которая максимально приближена по инфраструктуре к production environment.
Появилась полноценная команда DevOps из 8 человек, которая полностью отвечает за инфраструктуру и безопасность. Скорость разработки и количество релизов увеличились примерно в 5 раз.
Как это изменило структуру разработки в компании в целом (не только Back-end)
При поэтапном переходе от монолита к микросервисной архитектуре мы получили важный опыт и поняли, что подход с доменными командами является совершенно другой парадигмой в планировании, реализации и доставке изменений в production и что он должен сопровождаться соответствующими изменениями в организационной структуре. При разработке новой функциональности, кроме разработчиков, в процесс вовлечено много других специалистов: аналитики готовят требования, архитектор определяет зоны ответственности по доменным командам и формирует архитектурный подход, согласованием сроков доставки занимаются координаторы команд.

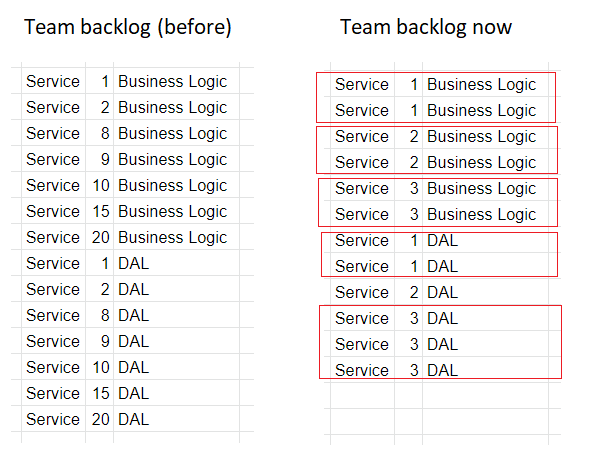
Доменные команды оценивают задачи и добавляют их в рабочий план (бэклог) в соответствии с приоритетами. Экспертные знания в своих сервисах позволяют им выполнять задачи качественнее и быстрее. В разработке появилась возможность не только накапливать, но и разбирать технический долг, ускорилась доставка сервисов в production. Качественное отличие проявилось в виде более частых гранулярных релизов. Доменные команды делают гранулярные технические релизы микросервисов, затем производят продуктовый релиз включением функциональности с админпанели.
Выводы
Это только небольшая часть описания процесса перехода. Многое осталось за кадром, в том числе и особенности работы ключевого направления команды продуктовой разработки. Наш опыт показал, что для масштабируемости разработки и реализации высоконагруженных систем с помощью микросервисной архитектуры важны не только технические, но и корректные менеджерские решения. При имплементации микросервисной архитектуры нужно учитывать потребность изменений на уровне организационной структуры всей компании, в нашем случае это был переход от collective code ownership к strong code ownership. Чтобы улучшить взаимодействие команд, разработчикам и менеджменту необходимо объединять усилия и улучшать процессы жизненного цикла разработки программного обеспечения.






![Атака на облачные Java-приложения и их защита [видео Eng]](https://bookflow.ru/wp-content/uploads/2022/03/Ataka-na-oblachnye-Java-prilozheniya-i-ih-zashhita-video-Eng-100x70.jpeg "Атака на облачные Java-приложения и их защита [видео Eng]")




 на 100 слоях")






