
Прим. перев.: в этой статье сербский инженер по масштабируемости нагруженного онлайн-проекта в подробностях рассказывает о своем опыте оптимизации большой БД на базе MySQL. Проведена она была для того, чтобы выдержать резкий рост трафика на сайт, случившийся из-за пандемии.

Примечание: первоначально эта статья была опубликована в блоге моего хорошего друга unstructed.tech.
База данных становится слишком большой или старой? Ее тяжело обслуживать? Что ж, надеюсь, я смогу немного помочь. Текст, который вы собираетесь прочитать, содержит реальный опыт масштабирования монолитной базы данных, лежащей в основе одного из сайтов Топ-250 (согласно alexa.com). На момент написания этой статьи chess.com занимал 215 место в мире по популярности. Ежедневно к нам заглядывали более 4 млн уникальных пользователей, а наши MySQL-базы обрабатывали в общей сложности более 7 млрд запросов. Год назад сайт ежедневно посещали 1 млн уникальных пользователей; в марте прошлого года их число увеличилось до 1,3 млн; сегодня более 4 млн человек заходят на chess.com ежедневно, а число сыгранных партий превышает 8 млн. Я, конечно, знаю, что это не сопоставимо с самыми крупными игроками на рынке, однако наш опыт все же может помочь в такой сложной задаче, как исправление монолитной базы данных и ее вывод на новый уровень производительности.
Примечание: Это моя первая статья, и она довольно длинная (и это при том, что мне пришлось вырезать примерно половину текста, чтобы сделать ее читаемой). Так что некоторые вещи могут оказаться не слишком понятными и недостаточно объясненными, и я прошу за это прощения. Свяжитесь со мной в LinkedIn, и мы сможем обсудить все вопросы более подробно.
Обновление: прочитав массу комментариев [к оригинальной публикации прим. перев.], я хотел бы добавить/уточнить несколько моментов. Мы широко используем кэширование иначе не продержались бы и дня. И да, мы используем Redis (зачастую выжимая из него максимум). Мы пробовали MongoDB и Vitess, но они нам не подошли.
Состояние, в котором мы находились пару лет назад
Где-то в середине 2019-го мы начали замечать, что основной кластер БД потихоньку становится чрезмерно громоздким. У нас также имелись три меньших по размеру и менее загруженных базы данных, но все данные в конечном итоге всегда оказывались в основной БД. Удивительно, но она была в довольно приличном состоянии для базы, которая начала свою работу более 12 лет назад. Не так много неиспользуемых/лишних индексов (существующие были преимущественно хороши). Мы постоянно отслеживали и оптимизировали тяжелые/медленные запросы. Значительная часть данных была денормализована. И речь идет не о каких-то посторонних ключах многие вещи были реализованы в самом коде (фильтрация, сортировка и т.п. с тем, чтобы БД работала только с самыми эффективными индексами), работающем на последней версии MySQL, и т.д., и т.п. Мы о ней не забывали, и в результате со временем она эволюционировала во вполне хороший инструмент.
Предостережение: я никого не призываю заниматься подобными микро-оптимизациями. Они работают для chess.com, для его масштаба. Любое решение перед реализацией тщательно тестируется, результаты внимательно оцениваются. Так что мы знаем, что оно работает для нас.
Самая большая проблема, с которой мы столкнулись в тот момент, состояла в том, что для изменения почти любой таблицы требовалось вывести половину хостов из ротации, провести ALTER , вернуть их в ротацию. А затем все это повторить для другой половины. Нам приходилось проводить эти операции в часы затишья, поскольку исключение половины хостов из работы в пиковое время, скорее всего, обрушило бы вторую половину. С ростом сайта старые функции получали новые воплощения, и нам часто приходилось проводить ALTER 'ы (те, кто в теме, поймут, о чем я). Процесс был бы гораздо менее напряженным, если бы мы могли исключить из ротации только небольшой набор таблиц, а не всю БД. Поэтому мы разработали 5-летний план для основного кластера (ох, какими наивными мы были. ), в котором прописали шаги по разбиению базы на множество более мелких. Это должно было упростить и облегчить обслуживание (ну, хоть с этим угадали. ). План исходил из годовых темпов роста в
25% (именно такие темпы наблюдались на тот момент).
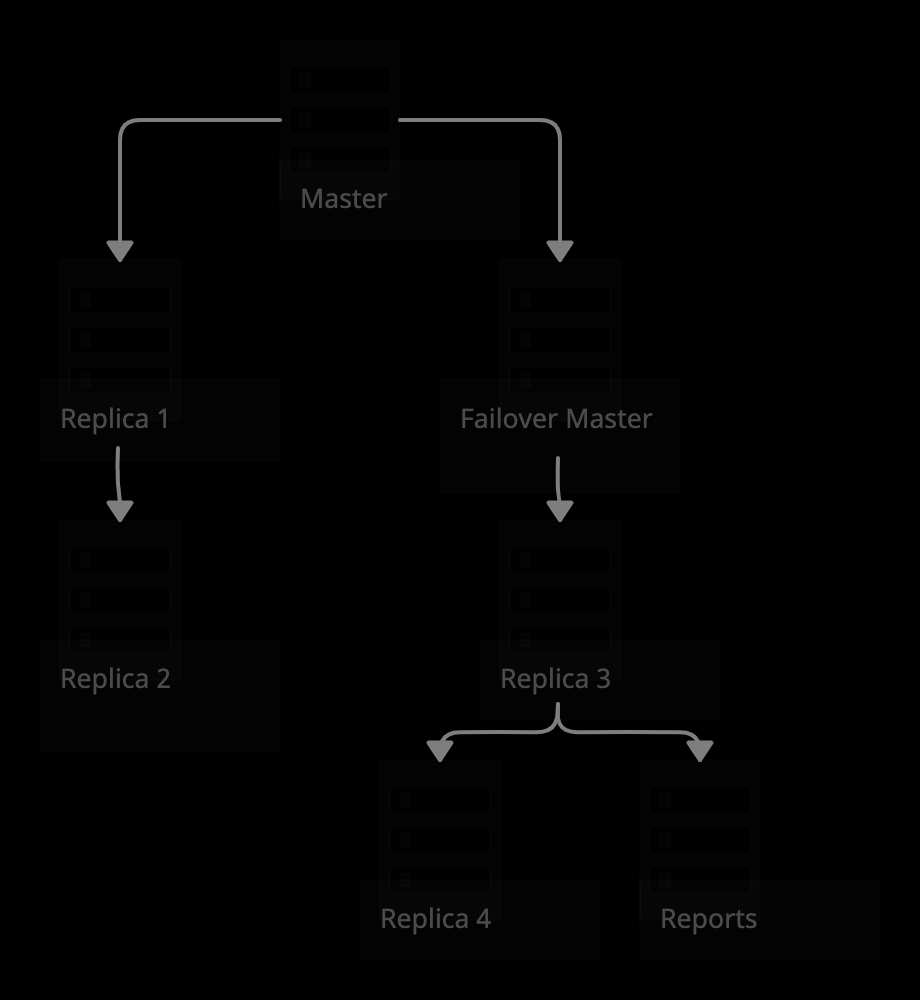
Где мы были около 2 лет назад
РЕАЛЬНАЯ проблема вносит коррективы в наш план
Все вы наверняка знаете о COVID-19 и суматохе, с ним связанной. Легко догадаться и о том, что мы вовсе не были ко всему этому готовы (не ожидали того воздействия, которое локдаун окажет на трафик). Интерес к шахматам взлетел до небес, как только (большая) часть Европы отправилась на самоизоляцию. Забавно, но можно было сказать, какая страна ввела локдаун, просто глядя на количество регистрирующихся пользователей по странам это было так очевидно. И все наши показатели взлетели до небес. Как ни странно, базы данных работали нормально (не супер, конечно, но вполне справлялись с трафиком). Но в то же время мы заметили, что хост reports не поспевал за хостами production (то есть частенько он отставал на 30-60 секунд в репликации), что заставило обратить внимание на поток репликации и его доступную пропускную способность. И она была практически полностью исчерпана (на пике потребления оставалось не более 5%). В тот момент мы уже понимали, что в США (откуда основная часть наших игроков) скоро также введут самоизоляцию. Это означало бы, что наши реплики не смогут обработать все операции записи в мастер (впрочем, это случилось бы, даже если мы просто продолжали медленно, но верно расти). Это был бы конец chess.com, поскольку код не готов к значительным задержкам репликации при чтении данных с реплик, а отправка всех SELECT 'ов на мастер привела бы к его падению. Цель стала ясна: снизить число операций записи в главный кластер, и сделать это как можно скорее. На самом деле это входило в наш изначальный план, только тот был растянут на пять лет. А у нас на все была пара месяцев.
Решение
Как снизить количество операций записи в БД? На первый взгляд все просто: определить самые нагруженные в этом смысле таблицы и выкинуть их из базы данных. Так мы просто разбиваем операции записи на два отдельных потока, не меняя их число. Это могут быть таблицы с большим числом INSERT 'ов, или таблицы без множества INSERT 'ов, но с записями, которые часто обновляются. Их просто надо определить в какое-нибудь другое место. Но как сделать это без простоя? Как вы догадываетесь, не все так просто.
Сначала мы выделили таблицы с наибольшим числом обновлений ( INSERT , DELETE или UPDATE ). Основная их часть была красиво сгруппирована в зависимости от функции, для которой использовалась (в большинстве таблиц, связанных с игрой, запись велась примерно с одинаковой скоростью и т. п.). В итоге мы получили список из 10-15 таблиц для 3 различных функций сайта. При их изучении проявилась еще одна проблема: поскольку мы не можем делать JOIN 'ы между базами на разных хостах, надо перенести все возможные таблицы, отвечающие за определенный функционал, чтобы упростить проект. Впрочем, этот момент был нам известен заранее, поскольку когда план только появился, мы уже имели успешный опыт похожей миграции для трех небольших, слабо задействованных таблиц в рамках проверки концепции (PoC).
Три упомянутых выше нагруженных функции это logs (не совсем функция и не совсем логи… просто неудачное название), games (чего и следовало ожидать от шахматной платформы) и puzzles (шахматные задачи-пазлы). В случае логов мы выделили три сильно изолированных таблицы (что означало минимальные изменения в запросах/коде). То же самое и для игр. Но в пазлах было задействовано более 15 таблиц, и запросы к ним включали массу JOIN -операций с таблицами, которые должны были остаться в основной БД. Мы мобилизовали свои войска, привлекли более половины бэкенд-разработчиков, разбили их на команды и совместными усилиями приступили к миграции.
Одна неделя ушла на перемещение логов в выделенную базу данных, работающую на двух хостах, что дало нам время на передышку, поскольку основная часть операций записи касалась именно их. Еще месяц потребовался на перемещение игровых баз (было очень страшно: любая ошибка привела бы к катастрофе, учитывая, что вся суть сайта именно в шахматных партиях). Два месяца ушло на перемещение пазлов. После всех этих действий загруженность канала репликации снизилась до 80% на пике то есть у нас появилось время перегруппироваться и распланировать предстоящие проекты немного тщательнее.
Исполнение
Итак, как же нам это удалось?
Как вы догадываетесь, у подобного предприятия имеются два аспекта: на стороне кода и на стороне базы данных, и оба требуют большой работы. На стороне кода есть несколько предварительных условий. Прежде всего, нужна система feature flag (она же feature toggle) либо внутренняя, либо сторонняя. Наша разработана на заказ и весьма обстоятельна (пожалуй, это отличная тема для новой статьи). Абсолютный минимум, который должен быть у такой системы, возможность открывать или запрещать доступ к тестовой функции в диапазоне от 0 до 100 процентов. Другая полезная вещь хорошее покрытие тестами. Несколько лет назад вся наша кодовая база была переписана с нуля, так что нам повезло (пару раз этот факт сильно выручал).
Что касается изменений кода и базы, кое-что можно делать параллельно, другие операции приходится делать последовательно. Проще всего начать с создания новой БД. Все наши новые базы данных извлекаются из основной: мы называем их partitions (партициями или разделами), а сам процесс partitioning (партиционированием, разбиением на разделы). Для размещения используется 2-хостовая схема (мастер и failover-мастер, т.е. реплика), но в принципе схема может быть любой.
В новом кластере создается база данных со схемой, идентичной схеме той базы, которую мы пытаемся разделить (именуя ее в соответствии с потребностями; в нашем случае первая называлась logs). Затем импортируется резервная копия основной базы данных, после чего мы делаем мастер partition-кластера репликой основного мастера (именно поэтому копируем схему и импортируем резервную копию). В результате новый кластер становится очередной репликой основного кластера, только база данных называется иначе. На некоторое время оставляем все как есть новая база просто реплицирует трафик и обновляется в связке с остальным кластером, пока мы работаем над кодовой частью проекта.
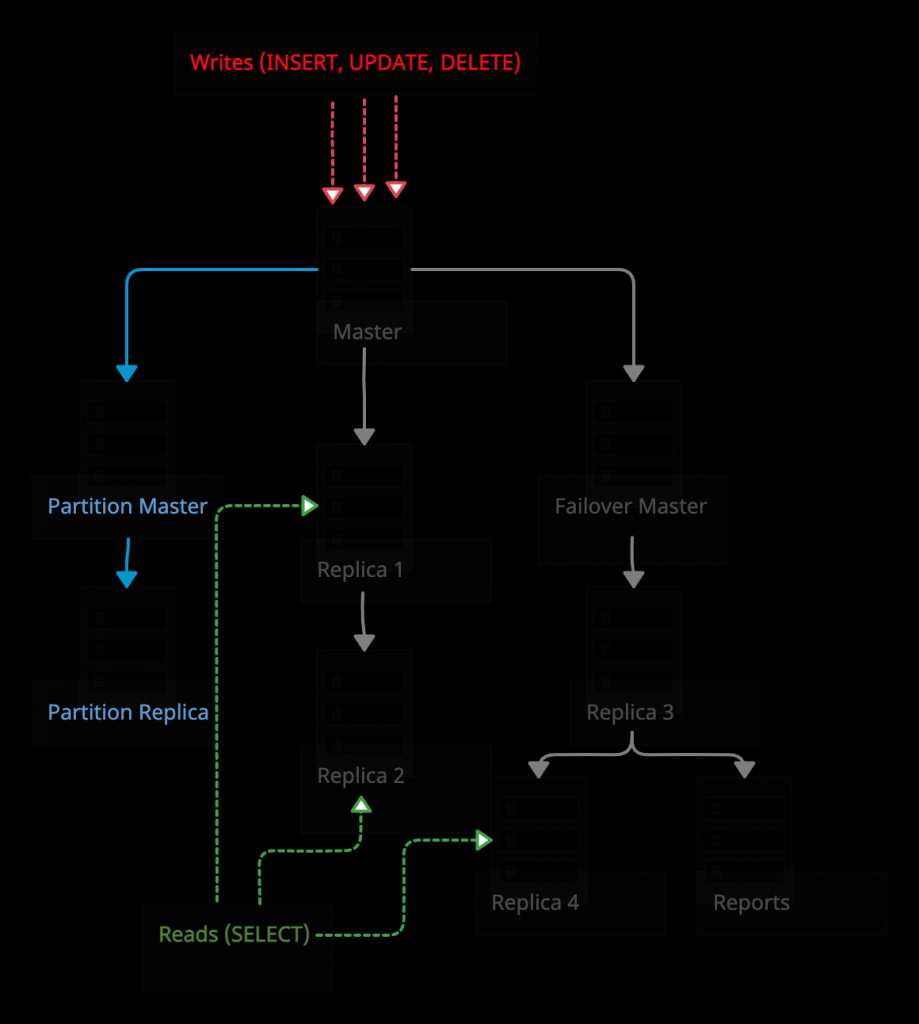
Так выглядит кластер после добавления новых хостов
До начала работы над данным проектом у нас, по сути, было открыто два подключения к базе данных из кода: read-only для работы с репликами и read/write для работы с мастером. Оба подключения проходили через HAProxy, чтобы попасть туда, куда требовалось. Первое, что мы сделали, создали параллельный набор подключений. В нем read/write идет к Partition Master, а read-only к Partition Replica.
Chess.com написан на PHP, так что я буду использовать PHP-примеры для иллюстрации необходимых изменений. При этом постараюсь максимально приблизить его к псевдокоду, чтобы все смогли понять, что именно происходит (вы будете удивлены, узнав, как много веб-сайтов из Топ-1000 написаны на PHP и насколько легко масштабировать PHP до этих высот. Пожалуй, хорошая тема для еще одной статьи).
Изменения кода сводятся к 3 вещам:
Удаление JOIN -запросов к таблицам, которые теперь обитают в разных базах данных.
Агрегирование, слияние и сортировка данных в коде (поскольку теперь не получится проводить некоторые из этих операций в БД)
Использование feature flag-системы для определения того, на какие хосты идут запросы.
Чтение данных
Хотя удаление JOIN 'ов и кажется простым, на самом деле таким не является. В следующих примерах я предполагаю, что таблицы games и additional_game_data перемещаются в базу данных в новом partition (примеры на псевдокоде, так что не ожидайте, что они будут идеальными). Итак, запрос, который выглядел следующим образом:
… теперь будет выглядеть так (поскольку мы больше не можем сделать JOIN с таблицей users ):
Мы убрали JOIN с таблицей users , выбор столбцов из users , условие для столбца из users в выражении с WHERE , сортировку и LIMIT по очевидным причинам. Теперь все это надо реализовать в коде. Прежде всего, нужна информация о пользователях. Давайте ее получим:
Здесь :userIDs это список идентификаторов пользователей, которые были получены в первом запросе. Теперь остается только объединить два набора данных и поместить их в проверочное условие feature flag. В конечном итоге мы получим нечто вроде приведенного ниже (псевдо-)кода. Оба return возвращают один и тот же результат:
Пурист может возразить, что это не самый оптимальный код, поскольку он может требовать многократной итерации, объединения и фильтрации данных в приложении и т.п. Все это правильно, но удар по базе данных все же сильнее. В целом, это гораздо более дешевый способ добиться нужного результата. То, что мы перенесли кучу сортировок, слияний, фильтраций из БД в код, очень помогло масштабированию БД.
Запись данных
Этот параграф мог бы оказаться совсем тривиальным, если бы не чертовы автоинкременты. Пожалуйста, еще раз взгляните на изображение с потоками данных после того, как мы все настроили.
Начну с решения проблемы автоинкрементов: все операции записи идут либо в основную БД, либо в новый partition-кластер (то есть feature flag разом принимает значение 0% или 100%). Никаких промежуточных вариантов. Если произойдет сбой и хотя бы один INSERT попадет в новый partition, partition-хосты полностью прекратят репликацию, а ряд запросов придется пропускать вручную или же начинать всю работу на уровне БД заново (удалять и воссоздавать partition-БД).
Например, если автоинкремент в мигрируемой таблице дошел до 1000 и случился сбой, из-за которого INSERT 'ы попали в новую partition, автоинкремент там будет принимать значения 1001, 1002 и т.д. Теперь предположим, что сбой устранен, и записи снова поступают в главную БД с инкрементами 1001, 1002. При репликации данных записей на новые хосты MySQL обнаружит, что там уже есть записи с такими инкрементами, и выдаст ошибку unique constraint violation . И нам придется все исправлять.
Все это не проблема, если используются UUID. Подробнее об этом речь пойдет далее в статье.
Пример кода (он еще проще, если используется обычный SQL просто надо использовать разные объекты для подключения к БД в if / else ):
Само переключение
Это как раз та ситуация, когда хороший инструмент для мониторинга БД (вроде PMM), мониторинг ошибок (типа Sentry) и feature toggling творят чудеса. Начинаем с простого: посылаем минимально возможный процент SELECT 'ов на новые partition-хосты (процент зависит от возможностей feature flag-системы). Смотрим на ошибки/исключения. Повторяем процесс, пока процент не вырастет до 100 (обычно на это уходит более недели). С помощью инструментов для мониторинга БД проверяем, что SELECT 'ы больше не затрагивают таблицы в основном кластере БД.
Постепенно переключаем операции чтения на partition-кластер
Если мигрируемые таблицы базируются на UUID считайте, что вам повезло. Мы просто повторяем процесс, описанных выше, для записи. Это сработает, поскольку к этому моменту все SELECT 'ы будут направляться на новые partition-хосты. И если мы будем писать прямиком в них (независимо от процента), то данные будут полными (одна часть попадет туда напрямую, другая будет реплицирована с мастера основной БД). При этом в главной БД не будет данных, напрямую записанных на новые хосты (это проблему можно было бы решить с помощью двунаправленной репликации, но это просто повысило бы сложность всего проекта). Это означает, что мы уже не можем перенаправить туда SELECT 'ы, поскольку данные неполны (ниже поговорим подробнее о том, как отыграть все назад). И аналогично тому, что сделано с чтением, продолжайте увеличивать процент запросов, пока он не достигнет 100%, а инструменты мониторинга не подтвердят, что переключение завершено. Теперь просто отключаем репликацию между мастером нового partition-кластера и основным кластером. Вот и все.
Увы, процесс не так прост, если используются первичные ключи с автоинкрементами. Или же прост в зависимости от того, как на него посмотреть. Но он определенно более напряженный. Нужно мгновенно переключить feature flag с нуля до 100%. В результате все либо будет работать, как ожидалось, либо нет: наличие нескольких запасных хостов для тестирования процесса переключения очень помогает; настоятельно рекомендую. Если все выглядит отлично (или хотя бы приемлемо), то репликация останавливается (как и в случае с UUID), а любые незначительные проблемы исправляются позже. Если же все пошло не по сценарию, придется вернуть все назад.
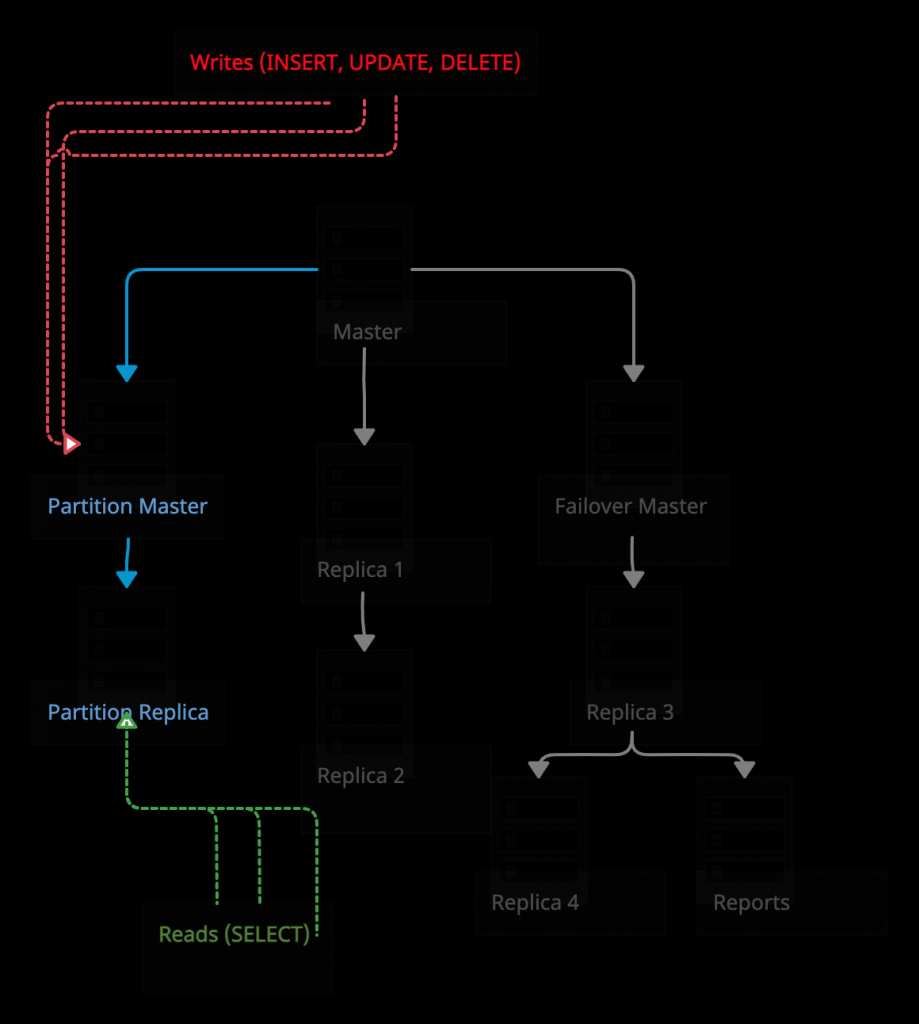 Мгновенное переключение операций чтения с мастера основного кластера на мастер partition-кластера (для первичных ключей с автоинкрементом)
Мгновенное переключение операций чтения с мастера основного кластера на мастер partition-кластера (для первичных ключей с автоинкрементом) 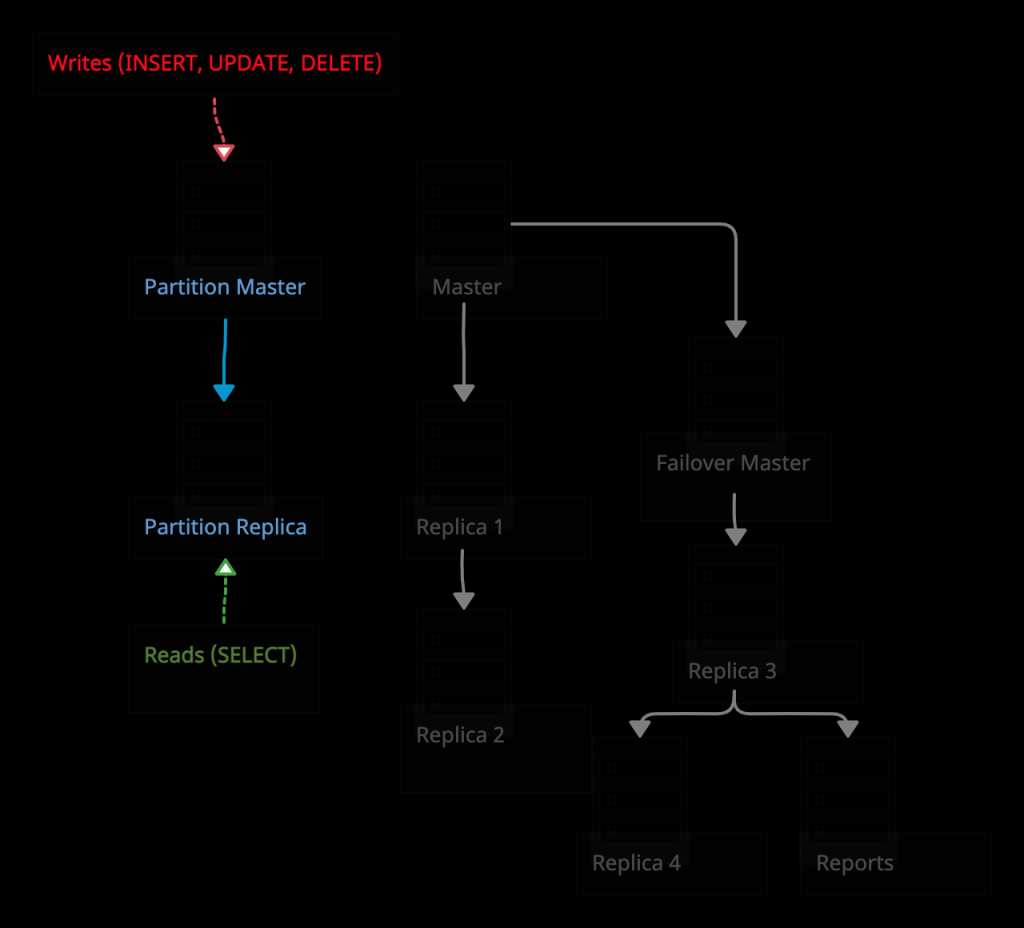 Конечный результат
Конечный результат
Как вернуть все назад
За последние пару лет мы создали 6 таких partitions, и только однажды наш план провалился (на самом деле, это была вина feature flag-системы вкупе с автоинкрементами). Опять же, трудоемкость отката зависит от того, используете вы автоинкременты или UUID.
В случае UUID отмена довольно проста. Просто перенаправьте операции записи и чтения (с помощью feature flag) обратно в основной кластер. Остановите репликацию на partition-хосты. Теперь, в зависимости от трафика, есть два пути: можно вручную установить, какие данные отсутствуют в главном кластере, и скопировать их туда, либо закопаться в бинлоги (если они включены), засучить рукава и скопировать недостающие данные. Могло быть и хуже (просто прочитайте следующий абзац).
Этот абзац про автоинкременты. Как и выше, перенаправьте операции записи и чтения в основной кластер. В данном случае просто скопировать данные не получится, поскольку основной кластер уже начал заполняться данными с теми же PK (автоинкрементами), которые существуют в новом partition. Так что придется копнуть поглубже. О простом копировании данных, вероятно, не может быть и речи, если PK хранятся в другом месте в качестве внешних ключей (FK). Возможно, вам больше повезет найти все это в бинлогах (если они включены).
К сожалению, хотя мы всегда были готовы отыграть любой потенциальный бардак еще до того, как у нас появился шанс познакомиться с ним впервые, когда он все-таки наступил, мы просто решили его проигнорировать. Нам повезло. Поскольку feature flag-система прокололась только на одном хосте, после переключения всех запросов на главный кластер потерялось несколько десятков тысяч автоматических сообщений, отправленных системой пользователям. И мы посчитали, что нет никакого смысла восстанавливать все эти записи, поскольку они использовали автоинкременты. Сбой продолжался минут пять, и пользователи от него не пострадали. Так что да, нам реально очень сильно повезло!
Результаты
А теперь о вкусняшках. Мы смогли настроить все новые partitions (я полагаю) таким образом, чтобы 95% запросов шли в мастер, а оставшиеся 5% в реплику/резервный (failover) мастер просто для того, чтобы держать MySQL наготове (на случай, если резерву внезапно придется заработать в полную силу). Это означает, что при мониторинге кластера нам достаточно наблюдать за состоянием мастера. Проводить операции ALTER очень просто, так как не нужно переживать о том, сможет ли один хост (пока на другом работает ALTER) обработать весь трафик.
С кодом не так все радужно необходимо удалить все условия, разбросанные по кодовой базе. На стороне БД нужно провести DROP всех мигрированных таблиц из основной базы данных, а в новом partition'е, наоборот, оставить только их. Теперь это безопасно, ведь репликация между ними не работает.
Закончить хочу комментарием от нашего легендарного сисадмина после того, как минисериал Ход королевы (The Queens Gambit), снятый по заказу Netflix, вызвал еще одну огромную волну трафика (подробнее об этом здесь):

Отвечаю: если бы мы не разбили наши базы, то последние два месяца (минимум) оказались бы для нас очень веселыми.
Бонус 1: Тонкости на что обратить внимание
Необходимо продолжать отправлять запросы SELECT на мастер главного кластера (если они изначально отправлялись на него) до тех пор, пока операции записи не будут переключены на мастер partition-кластера. Это связано с задержкой репликации, которая могла возникнуть между двумя мастерами.
Всегда проверяйте, что feature flag'и переключились на каждом из хостов. Как я упоминал выше, однажды случилось так, что на одном хосте они не сработали во время переключения записи на одном из partition'ов. Это причинило нам немало страданий.
Нам пришлось дублировать сущности Doctrine, чтобы убрать зависимость от сущностей в других базах данных.
Дублирование было необходимо, поскольку мы хотели оставить старый (legacy) код за feature flag'ом и в то же время использовать новые сущности без JOIN 'ов.
Из-за специфики работы Doctrine нам пришлось поместить новые сущности в отдельное пространство имен.
Кэширование может стать проблемой, если кэширующий код завязан на соединение/базу данных и т.д.
Бонус 2: Немного статистики
Наверное, вы, как и я, обожаете графики. Что ж, наслаждайтесь (все они получены на мастере в основном кластере):
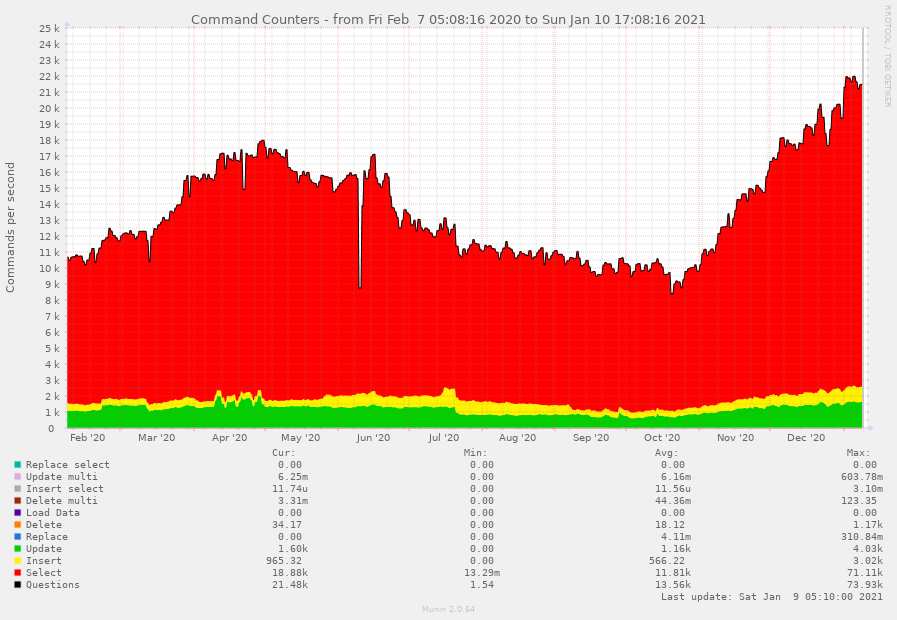 Число команд MySQL (мы начали работать над разделением данных в марте). Как видно, нам удалось сократить число запросов, хотя трафик продолжал расти.
Число команд MySQL (мы начали работать над разделением данных в марте). Как видно, нам удалось сократить число запросов, хотя трафик продолжал расти. 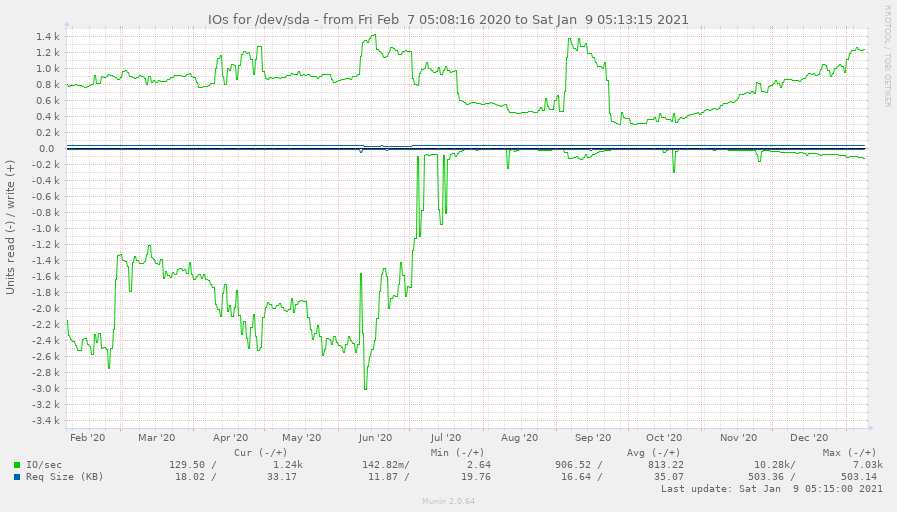 Статистика I/O диска. В июле нам удалось добиться того, что запросы почти не приводили к дисковым операциям (благодаря разбиению и оптимизации запросов, которые ранее приводили к появлению временных таблиц на диске
Статистика I/O диска. В июле нам удалось добиться того, что запросы почти не приводили к дисковым операциям (благодаря разбиению и оптимизации запросов, которые ранее приводили к появлению временных таблиц на диске 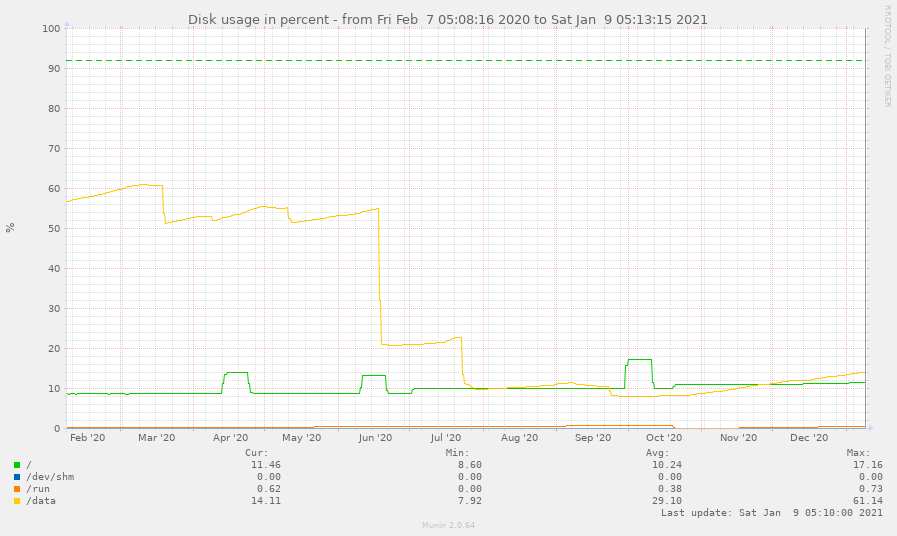 Использование диска – выглядит прелестно, не так ли?
Использование диска – выглядит прелестно, не так ли? 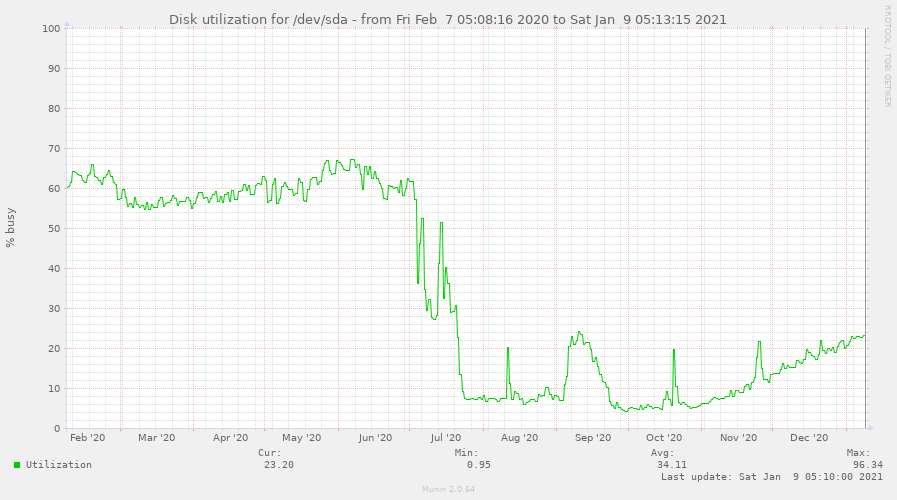 Использование диска
Использование диска











 на 100 слоях")






