
В настоящее время HDFS является подпроектом Apache Hadoop. Экземпляр HDFS содержит огромное количество серверов, каждый из которых хранит часть файловой системы. Типичный размер файла в HDFS составляет гигабайты или терабайты, поэтому приложения будут иметь большие наборы данных. Однажды созданный файл не нужно изменять, т.е. он работает по модели доступа «запись один раз чтение много».

Кластер HDFS состоит из главного сервера (namenode), который управляет пространством имен файловой системы и контролирует доступ к файлам. Другие узлы в кластере являются серверами datanodes, которые управляют хранилищем, подключенным к узлам, а также отвечают за создание/удаление/репликацию блоков по указанию namenodes. HDFS написана на языке Java, поэтому любые узлы, поддерживающие Java, могут запускать nameNode или dataNode приложения.
В этом руководстве представлена шпаргалка по командам Hadoop HDFS. Она пригодится вам при работе с этими командами в распределенной файловой системе Hadoop). Ранее в командах использовался hadoop fs, сейчас он устарел, поэтому мы используем hdfs dfs. Все команды Hadoop вызываются скриптом bin/hadoop. Эта шпаргалка содержит множество команд, я бы сказал, почти все команды, которые часто используются как разработчиками, так и администраторами Hadoop. Она довольно полная, я также показывает все опции, которые могут быть использованы одной и той же командой. В любом случае, если при выполнении команды вы получаете ошибку, не паникуйте и просто проверьте синтаксис команды, возможно, проблема в синтаксисе команды или в источнике или пункте назначения, который вы указали.
Мы сгруппировали команды в следующие категории:
1) Список файлов
2) Чтение/запись файлов
3) Загрузка/выгрузка файлов
4) Управление файлами
5) Владение и проверка
6) Файловая система
7) Администрирование
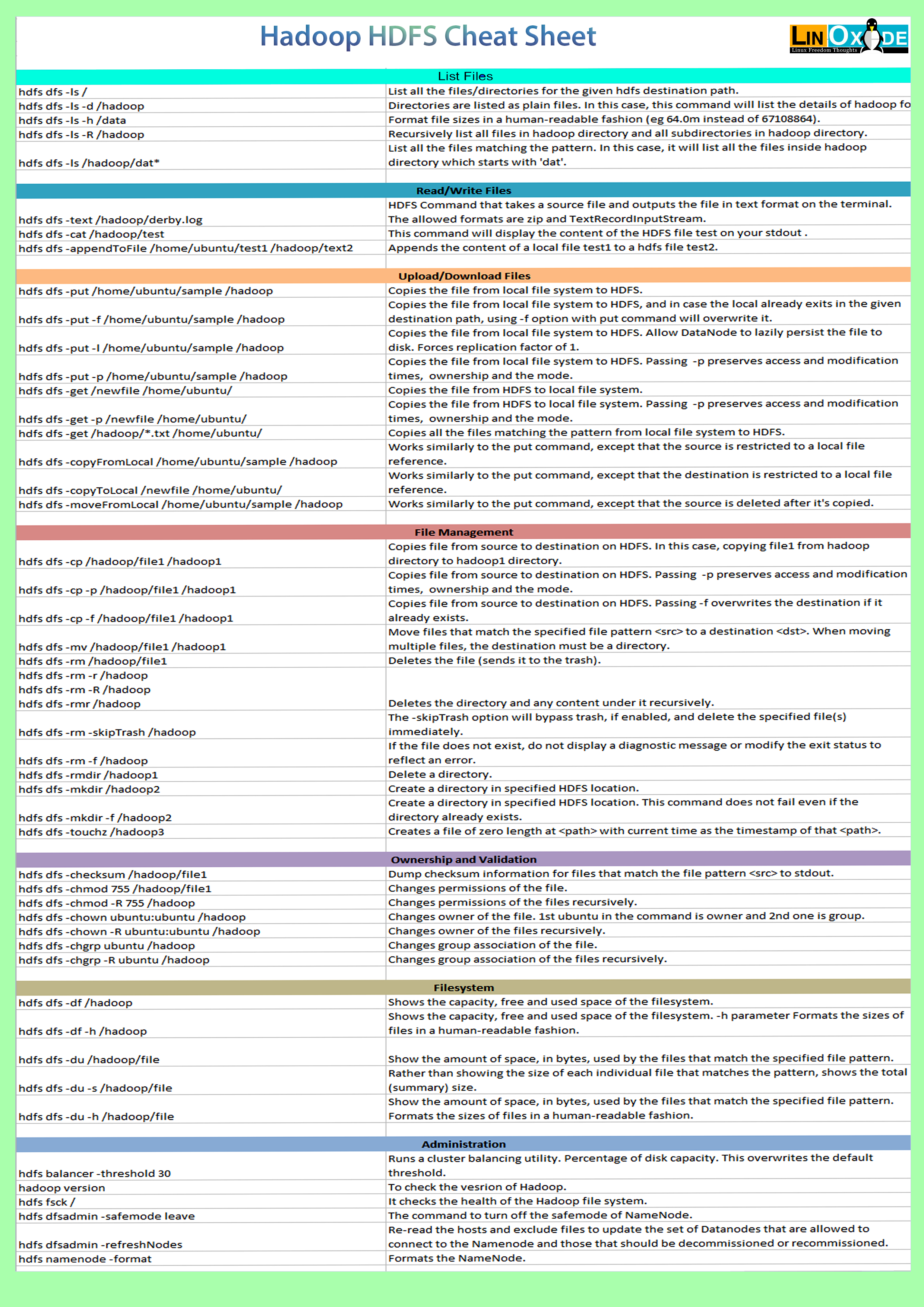
Вы можете скачать отсюда pdf-версию шпаргалки по командам hadoop hdfs или распечатать файл изображения формата A4.











 на 100 слоях")






