Разница в работе QoS на IOS. Этот документ покрывает вопросы QoS, связанные с реализацией качества обслуживания на маршрутизаторах Cisco. Работа QoS на коммутаторах Cisco в данном документе не затрагивается.

Реализация QoS на платформах с IOS XE имеет существенное отличие от реализации на платформах с классическим IOS. Нижеописанное поведение характерно для IOS XE начиная с версии 16.9.
Планировщик с 3 параметрами
Первое отличие в реализации QoS на IOS XE от реализации в классическом IOS заключается в том, что в планировщике можно контролировать 3 параметра вместо 2:
- Minimum – bandwidth
- Excess – bandwidth remaining
- Maximum – shape
В конфигурации по умолчанию планировщик на IOS XE будет делить excess bandwidth между классами поровну, в классическом IOS – пропорционально.
Учтите, что вы не можете сконфигурировать bandwidth и bandwidth remaining в одной и той же policy-map.Разница в работе QoS на IOS. Для лучшего понимания рассмотрим пример QoS, сконфигурированного на платформе с IOS XE.
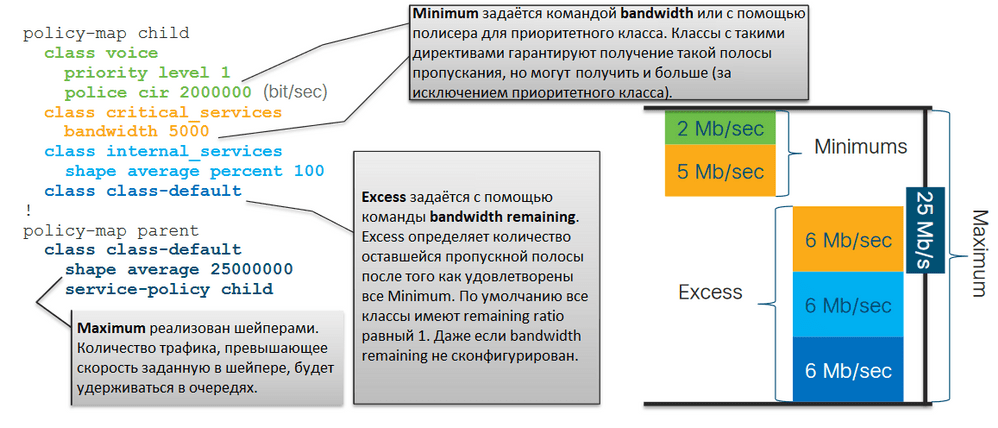
На картинке выше изображен двухуровневый иерархический policy-map: родительский с шейпером и дочерний с классами трафика. Maximum задаётся в родительском policy-map с помощью шейпера, то есть весь трафик не должен превышать 25 Мбит/с в данном случае. В дочернем policy-map мы задаём Minimum для каждого класса трафика, то есть то количество трафика, которое мы гарантируем данному классу. Для приоритетного класса voice мы определяем гарантированное количество трафика, равное 2 Мбит/с, для класса critical_services – 5 Мбит/с. Для остальных классов Minimum не задаётся. После того как удовлетворены требования всех Minimum, весь остальной трафик (Excess), превышающий гарантированные полосы, будет распределятся между всеми классами равным образом. Обратите внимание на то, что Minimum для приоритетного класса задан фиксированным значением. То есть даже если остаётся неиспользованная полоса пропускания, мы всё равно не сможем превысить заданное для этого класса значение в 2 Мбит/сек.
Существуют два способа управлять оставшейся пропускной способностью:
- bandwidth remaining ratio X, где X – это значение в диапазоне от 1 до 1000, с переменным базовым показателем.
- bandwidth remaining percent Y, где Y – это значение в диапазоне от 1 до 100, с фиксированным базовым показателем равным 100.
Базовый показатель bandwidth remaining percent (BR%) остается неизменным по мере добавления классов в конфигурацию. Он всегда 100%.
Базовый показатель bandwidth remaining ratio (BRR) регулируется по мере добавления дополнительных классов очередей в конфигурацию с настроенным BRR или без него. То есть базовый показатель в данном случае – это сумма всех сконфигурированных ratio или ratio по умолчанию, который равен 1.
Теперь сравним поведение планировщиков с 2 и 3 параметрами.
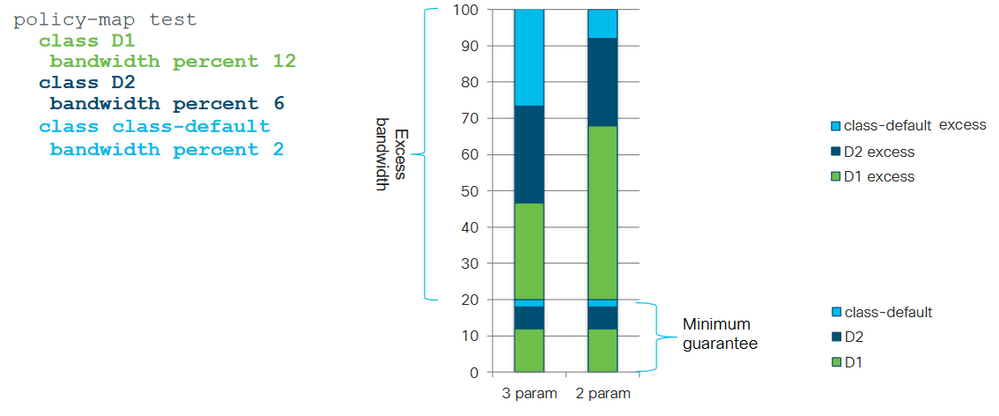
Планировщики с 2 параметрами (IOS) распределяют избыточную полосу пропускания между классами пропорционально. Если указанная выше policy-map перегружена, 80% оставшейся полосы пропускания пропорционально делится между всеми тремя очередями. Это дает ещё большее преимущество трафику, которому изначально был придан большой вес. Для понимания рассчитаем количество полосы пропускания, которую получит класс D1 при работе планировщика с 2 параметрами:
12% + (12 / (12+6+2) * 80%) = 60%
Планировщики с 3 параметрами (IOS XE) распределяют избыточную полосу пропускания между классами поровну. Если указанная выше policy-map перегружена, 80% оставшейся полосы пропускания поровну делится между всеми тремя очередями. Для понимания рассчитаем количество полосы пропускания, которую получит класс D1 при работе планировщика с 3 параметрами:
12% + (80% / 3) = 12% + 26,67% = 38,67%
Чтобы получить на IOS XE поведение планировщика, похожее на поведение планировщика с 2 параметрами, используйте конфигурацию BRR. Это не дает возможность задать никаких Minimum, но excess bandwidth будет обрабатываться так же, как и на платформах, использующих планировщик с 2 параметрами.
Рассмотрим ещё несколько примеров, как планировщик с 3 параметрами обрабатывает трафик.
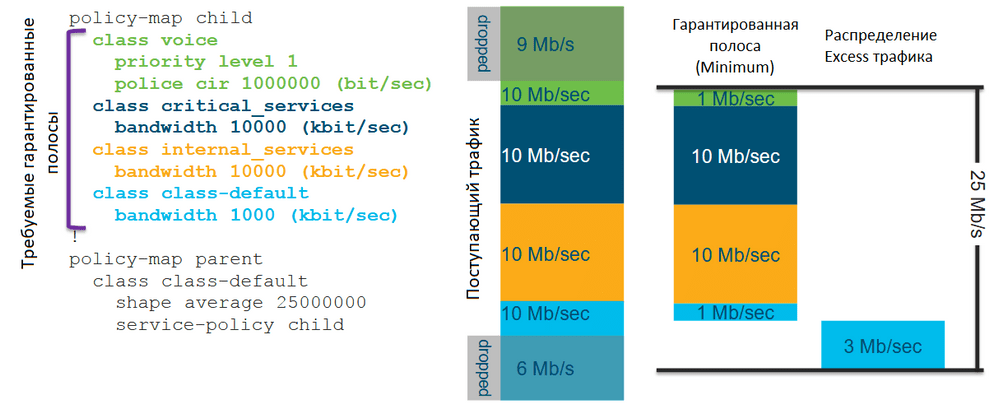
На картинке выше изображен двухуровневый иерархический policy-map. С помощью шейпера в родительском policy-map задан Maximum, равный 25 Мбит/с. В дочернем policy-map для приоритетного класса voice задано гарантированное количество трафика (Minimum), равное 1 Мбит/с, для класса critical_services – 10 Мбит/с, для класса internal_services – 10 Мбит/с и для неклассифицированного трафика (class-default) – 1 Мбит/с.
На вход поступает 10 Мбит/с трафика класса voice, 10 Мбит/с трафика класса critical_services, 10 Мбит/с трафика класса internal_services и 10 Мбит/с неклассифицированного трафика. В соответствии с конфигурацией система пропустит 1 Мбит/с трафика класса voice, так как гарантированное количество трафика в приоритетной очереди задаётся полисером, который отбросит весь трафик, превышающий указанное значение. Также система пропустит по 10 Мбит/с трафика классов critical_services и internal_services, который соответствует сконфигурированной полосе, гарантированной трафику для данных классов. А также система пропустит 1 Мбит/с неклассифицированного трафика.
Сумма гарантированных полос даёт нам 22 Мбит/с. Получается, у нас есть ещё полоса, равная 3 Мбит/с для Excess траффика всех классов, которая в соответствии с конфигурацией должна распределиться равномерно между всеми классами. Но так как в данном случае Excess трафик есть только у неклассифицированного трафика, то вся эта оставшаяся полоса достанется ему.
В следующем примере рассмотрим сценарий с BRR.
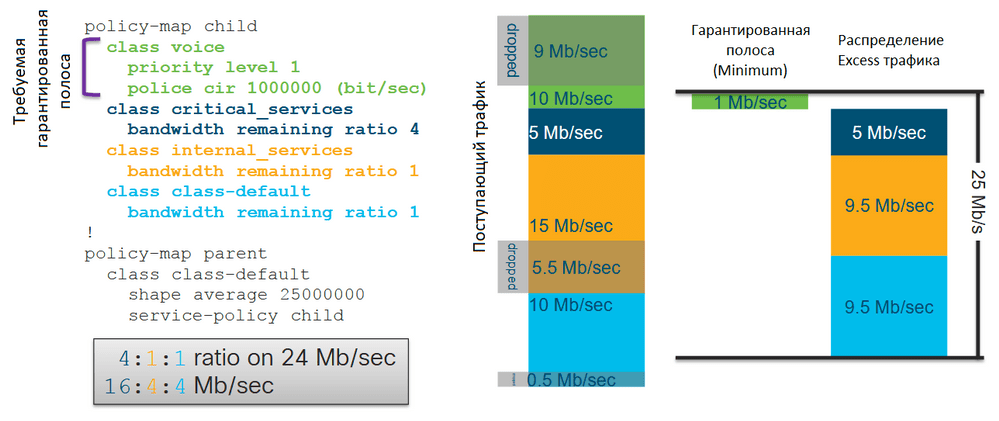
На картинке выше изображен двухуровневый иерархический policy-map. С помощью шейпера в родительском policy-map задан Maximum, равный 25 Мбит/с. В дочернем policy-map для приоритетного класса voice задано гарантированное количество трафика (Minimum), равное 1 Мбит/с, для класса critical_services задан ratio, равный 4, для класса internal_services и неклассифицированного трафика (class-default) задан ratio, равный 1.
На вход поступает 10 Мбит/с трафика класса voice, 5 Мбит/с трафика класса critical_services, 15 Мбит/с трафика класса internal_services и 10 Мбит/с неклассифицированного трафика. В соответствии с конфигурацией система пропустит 1 Мбит/с трафика класса voice, так как гарантированное количество трафика в приоритетной очереди задаётся полисером, который отбросит весь трафик, превышающий указанное значение. Для остальных классов гарантированная полоса не сконфигурирована.
Получается, у нас остаётся 24 Мбит/с нераспределённой полосы и суммарный ratio, равный 6. Приведём расчёт полосы для Excess трафика класса critical_services
24 / (4+1+1) * 4 = 16
Для классов internal_services и class-default получим
24 / (4+1+1) * 1 = 4
Это в итоге даёт нам следующие расчётные значения для оставшихся классов трафика: 16 Мбит/с для класса critical_services, 4 Мбит/с для класса internal_services и 4 Мбит/с для неклассифицированного трафика. Но так как у нас есть только 5 Мбит/с входящего трафика для класса critical_services, после того как система пропустит их, у нас останется ещё полоса, равная 19 Мбит/с. Так как ratio обоих оставшихся двух классов равно 1, то эта оставшаяся полоса, равная 19 Мбит/с будет распределена между ними равномерно. То есть трафик класса internal_services и неклассифицированный трафик получат полосы по 9,5 Мбит/с.
В следующем примере рассмотрим сценарий с BR%.
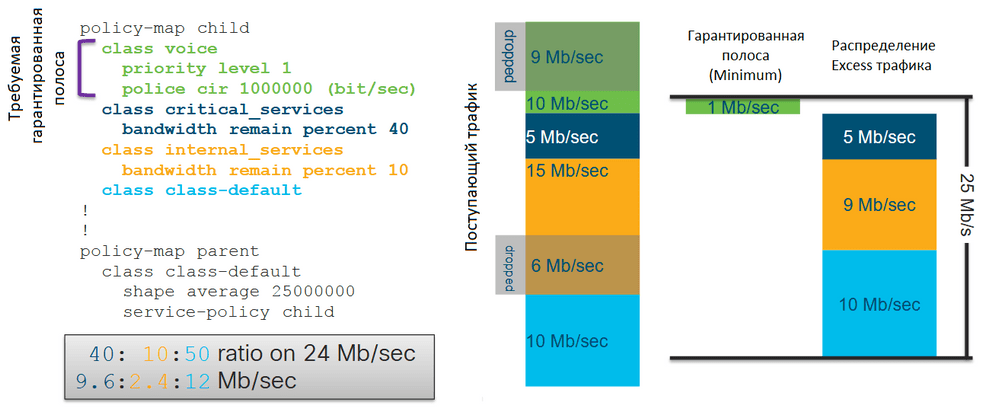
На картинке выше изображен двухуровневый иерархический policy-map. С помощью шейпера в родительском policy-map задан Maximum, равный 25 Мбит/с. В дочернем policy-map для приоритетного класса voice задано гарантированное количество трафика (Minimum), равное 1 Мбит/с, для класса critical_services задан remain perсent, равный 40, для класса internal_services – равный 10 и для неклассифицированного трафика (class-default) remain perсent не задан, то есть получается 50 (недостающие до 100%).
На вход поступает 10 Мбит/с трафика класса voice, 5 Мбит/с трафика класса critical_services, 15 Мбит/с трафика класса internal_services и 10 Мбит/с неклассифицированного трафика. В соответствии с конфигурацией система пропустит 1 Мбит/с трафика класса voice, так как гарантированное количество трафика в приоритетной очереди задаётся полисером, который отбросит весь трафик, превышающий указанное значение. Для остальных классов гарантированная полоса не сконфигурирована.
Получается, у нас остаётся 24 Мбит/с нераспределённой полосы. Это в итоге даёт следующие расчётные значения для оставшихся классов трафика: 9,6 Мбит/с для класса critical_services, 2,4 Мбит/с для класса internal_services и 12 Мбит/с для неклассифицированного трафика. Но так как у нас есть только 5 Мбит/с входящего трафика для класса critical_services, после того как система пропустит их, у нас останется ещё полоса, равная 19 Мбит/с. Так как конфигурация гарантирует неклассифицированному трафику 12 Мбит/с, а по факту приходит только 10 Мбит/с, то система пропустит эти 10 Мбит/с неклассифицированного трафика, а оставшаяся полоса пропускания в 9 Мбит/с достанется трафику класса internal_services.
Опция Queue—limit
Классический IOS предоставляет возможность определять queue-limit только на основании количества пакетов. В IOS XE определять queue-limit можно не только на основании количества пакетов, но и на основании времени и количества байтов.
Подходы к формированию глубины очереди на основе времени и на основе количества байтов по сути одинаковы, поскольку время просто преобразуется в байты в зависимости от скорости интерфейса (или родительского шейпера).
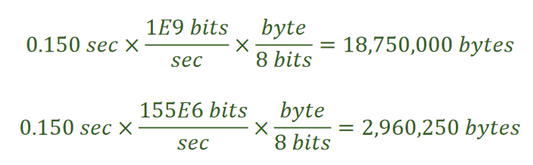
Выше приведены два примера расчёта количества передаваемых байтов с пакетами размером 1500 байт при 150 ms задержке для Gigabit интерфейса (верхний) и OC3 (155 Мбит/с) интерфейса (нижний).
Вы можете использовать одну и ту же policy-map для нескольких интерфейсов с разной скоростью.
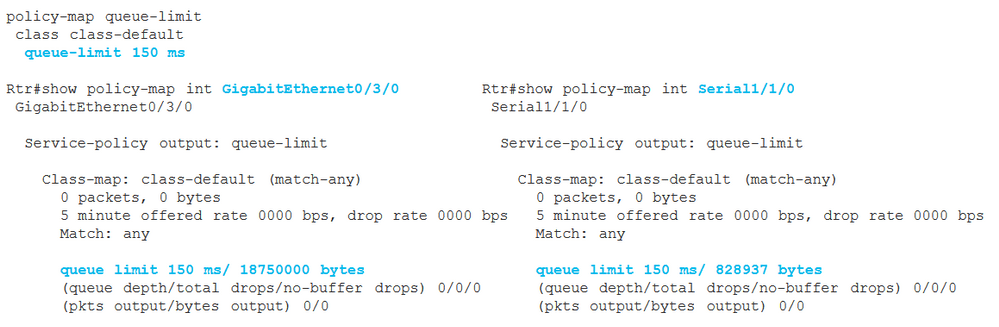
В примере выше мы видим, что одна и та же политика с глубиной очереди 150 ms применена к интерфейсам с разной скоростью. При этом глубина очереди в байтах будет пересчитываться в зависимости от пропускной способности интерфейса.
Важно отметить, что определение глубины очереди на основе времени или количества байтов даёт последовательный профиль задержки, в отличие от сценария, когда глубина очереди задаётся в количестве пакетов.
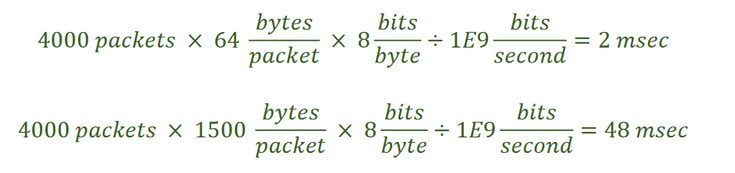
Из расчётов, приведённых выше, мы видим, что при определении глубины очереди в пакетах в секунду для 4000 пакетов размером 64 байта на гигабитном интерфейсе задержка составит 2 мс, а для такого же количества пакетов размером 1500 байт – 48 мс. В случае же использования определения глубины очереди на основе времени или количества байтов задержка будет одинаковой для пакетов с разной длиной.
В классическом IOS по умолчанию queue-limit равен 64 пакетам для всех очередей. В IOS XE для приоритетной очереди глубина очереди равна 512 пакетам, а для остальных очередей 50 мс (25 мс для ESP40), но не менее 64 пакетов.
!!!Не изменяйте глубину очереди для приоритетной очереди без особой необходимости.
Платформы на IOS XE будут игнорировать конфигурацию следующих параметров буферов для интерфейсов: hold-queue интерфейсов и глобальная конфигурация буферов. CLI отображает применение команд, но введённые команды не влияют на пересылку трафика или поведение QoS.
Как мы уже отметили ранее, для всех типов очередей, кроме приоритетной, глубина очереди по умолчанию равна 50 мс. Соответственно, количество пакетов в очереди будет рассчитываться следующим образом:

Если для класса сконфигурирован параметр bandwidth, значит скорость, указанная в команде, будет использоваться в качестве переменной speed в формуле для расчёта глубины очереди данного класса, приведённой выше.
Если для класса сконфигурирован параметр bandwidth percent, значит в качестве переменной speed будет использоваться процент от скорости, указанной в родительском шейпере.
Если для класса сконфигурирован параметр shape, значит в качестве переменной speed будет использоваться значение шейпера, указанного в команде.
Если сконфигурирован только bandwidth remaining, значит в качестве переменной speed будет использоваться значение, указанное в родительском шейпере.
Рассмотрим пример, как рассчитывается глубина очереди.
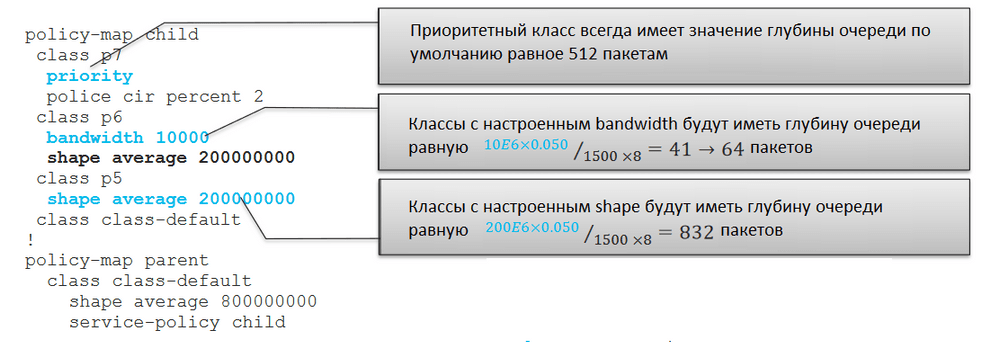
Как упоминалось ранее, приоритетная очередь всегда будет иметь значение глубины по умолчанию, равное 512 пакетам. Класс p6 имеет сконфигурированные значения bandwidth и shape. В данном случае для расчёта глубины очереди приоритет отдаётся значению, указанному в bandwidth. В соответствии с формулой, приведённой на картинке выше, получаем значение 41. Но мы уже отмечали, что глубина очереди не может быть меньше 64, поэтому для класса p6 значение queue-limit будет 64 пакета. Для класса p5 сконфигурирован shape. В соответствии с приведённой выше формулой значение глубины очереди будет 832 пакета.
Ещё один пример с расчётом глубины очереди.

Класс p6 имеет сконфигурированные значения bandwidth remaining rate и shape. В данном случае расчёт глубины очереди основывается на значении, указанном в shape. В соответствии с формулой, приведённой на картинке выше, получаем значение 125 пакетов. Для класса p5 сконфигурирован только bandwidth remaining rate, а значит для расчёта глубины очереди будет использоваться значение шейпера, указанного в родительском policy-map. В соответствии с приведённой выше формулой значение глубины очереди будет 333 пакета.
Два уровня приоритетных очередей
Классический IOS предоставлял возможность задать только одну приоритетную очередь. На платформах с IOS XE есть возможность сконфигурировать два уровня для LLQ. Приоритетную очередь 1 уровня (priority level 1) рекомендуется использовать для голосового трафика, а приоритетную очередь 2 уровня для видео. Обработка трафика происходит следующим образом. Сначала полностью опустошается приоритетная очередь 1 уровня, затем полностью опустошается приоритетная очередь 2 уровня и только после этого система приступает к обработке трафика остальных классов.
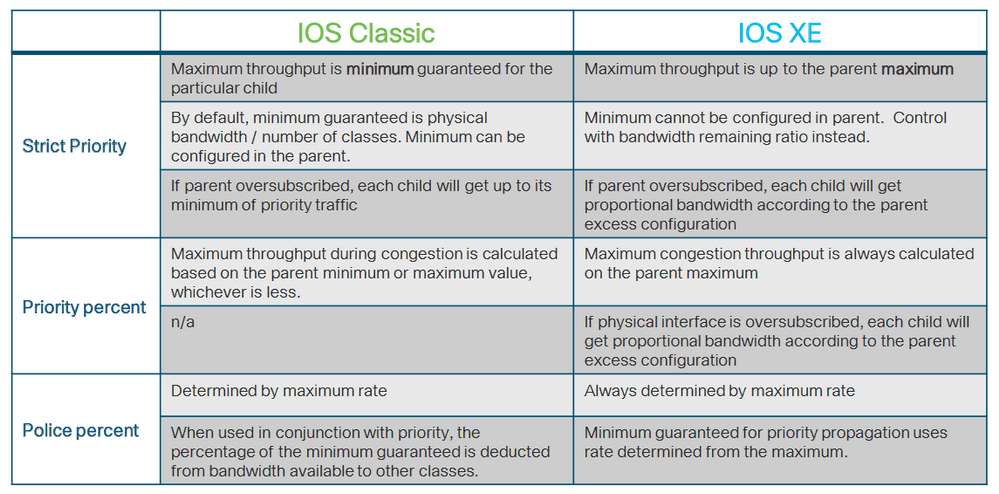
Между поведением приоритетных очередей на платформах с классическим IOS и платформах с IOS XE есть существенная разница. На платформах с IOS XE приоритетная очередь, сконфигурированная без полисера, будет потреблять всю доступную полосу пропускания. Все остальные классы в этой политике не смогут использовать bandwidth для резервирования minimum. В классическом IOS приоритетная очередь, сконфигурированная без полисера, будет потреблять 99% доступной полосы, а 1% зарезервируется для всех оставшихся классов трафика.
Полный список различий в таблице ниже.
QoS для туннелей
На платформах с классическим IOS можно было одновременно применять policy-map с очередями и на туннельный интерфейс, и на физический интерфейс, через который строился этот туннель. То есть система выполняла дважды классификацию и дважды очередизацию.
На платформах с IOS XE в процессе обработки трафик можно помещать в очереди только один раз. То есть конфигурация policy-map с очередями на туннельном интерфейсе и физическом интерфейсе не поддерживается. Доступен только сценарий, когда на туннельном интерфейсе сконфигурирован policy-map с очередями, а на физическом – policy-map с шейпером для class-default.
Если сконфигурирован policy-map с очередями на туннельном интерфейсе и на физическом интерфейсе (можно сконфигурировать только с class-default), то пакеты будут обработаны туннельной политикой, а затем пройдут через class-default в политике на интерфейсе.
Если сконфигурирован policy-map с очередями на туннельном интерфейсе, а на физическом интерфейсе policy-map без очередизации, то пакеты с туннеля пойдут в обход политики на интерфейсе.
Если сконфигурирован policy-map без очередей на туннельном интерфейсе, а на физическом интерфейсе policy-map с очередями, то пакеты с туннеля обработаются сначала политикой на туннеле, а затем политикой на интерфейсе.
Если на туннельном и физическом интерфейсах сконфигурированы политики без очередей, то пакеты будут обработаны туннельной политикой, а политика на интерфейсе не произведёт никакого действия.
Игнорирование параметров шейпера
Платформы с IOS XE игнорируют параметры bc и be, заданные в команде shape.

Вы можете их сконфигурировать, но они никак не повлияют на поведение системы.
При этом для полисера конфигурирование и обработка параметров bc и be происходит так же, как и в классическом IOS.
Существует ещё ряд отличий в реализации QoS на IOS XE от реализации в классическом IOS, но это специфические для платформ особенности, которые требуют отдельного рассмотрения.
Возможно вам будет интересно:
MU-MIMO Wi-Fi — 13 вещей, которые необходимо знать
Подборка программ — инструментов для системного администратора
ТОП книг для системного администратора 2019. Cisco CCNA
Примеры скриптов PowerShell для системного администрирования











 на 100 слоях")






