
Современные программисты должны не только эффективно программировать, но и знать надлежащие инженерные практики, позволяющие сделать кодовую базу стабильной и качественной.
В чем же разница между программированием и программной инженерией? Как разработчик может управлять живой кодовой базой, которая развивается и реагирует на меняющиеся требования на всем протяжении своего существования?
Основываясь на опыте Google, инженеры-программисты Титус Винтерс и Хайрам Райт вместе с Томом Маншреком делают откровенный и проницательный анализ того, как ведущие мировые практики создают и поддерживают ПО. Речь идет об уникальной инженерной культуре, процессах и инструментах Google, а также о том, как эти аспекты влияют на эффективность разработки.
Вы изучите фундаментальные принципы, которые компании разработчиков ПО должны учитывать при проектировании, разработке архитектуры, написании и сопровождении кода.
Системы и философия сборки
Если спросить инженеров в Google, что больше всего им нравится в компании (помимо бесплатной еды и первоклассного оборудования), то можно услышать удивительный ответ: им нравится система сборки. В Google было потрачено много сил и времени на создание собственной системы сборки с нуля. Усилия оказались настолько успешными, что Blaze — основной компонент системы сборки — несколько раз был повторно реализован экс-гуглерами в других компаниях2. В 2015 году Google наконец открыла исходный код Blaze под названием Bazel (https://bazel.build).
Назначение системы сборки
По сути, все системы сборки предназначены для преобразования исходного кода, написанного инженерами, в выполняемые двоичные файлы, понятные машинам. Хорошая система сборки обычно обладает двумя важными свойствами:
Скорость
Разработчик должен иметь возможность ввести одну команду, чтобы запустить сборку и получить двоичный файл в считанные секунды.
Безошибочность
Каждый раз, когда разработчик запускает сборку на любом компьютере, он должен получать один и тот же результат (при условии, что исходные файлы и другие входные данные совпадают).
Многие старые системы сборки пытаются найти компромисс между скоростью и безошибочностью, используя короткие пути, которые могут привести к получению несогласованных сборок. Bazel избавил разработчиков от необходимости выбирать между скоростью и безошибочностью.
Системы сборки предназначены не только для людей; их также могут использовать машины, чтобы автоматически создавать сборки для тестирования кода или выпуска продукта в продакшен. Фактически большинство сборок в Google запускаются автоматически, а не вручную. Почти все наши инструменты разработки так или иначе связаны с системой сборки, что дает огромную выгоду всем, кто работает с нашей базой кода. Вот небольшой пример использования нашей автоматизированной системы сборки:
- Код автоматически собирается, тестируется и передается в продакшен без участия человека. Разные команды проводят сборки с разной скоростью: одни еженедельно, другие — ежедневно, а третьи — настолько быстро, насколько это возможно (глава 24).
- Изменения, внесенные разработчиком, автоматически тестируются, когда он отправляет их для обзора (глава 19), благодаря чему автор изменений и рецензент могут сразу увидеть любые проблемы, возникшие из-за изменений на этапе сборки или тестирования.
- Изменения повторно тестируются непосредственно перед включением их в главную ветвь репозитория, что значительно уменьшает вероятность сохранения неработоспособных изменений.
- Авторы низкоуровневых библиотек могут тестировать свои изменения во всей базе кода и гарантировать, что эти изменения безопасны для миллионов тестов и двоичных файлов.
- Инженеры могут вносить крупномасштабные изменения, затрагивающие десятки тысяч исходных файлов (например, переименовывать общий символ), и безопасно отправлять в репозиторий и тестировать эти изменения. Подробнее о крупномасштабных изменениях в главе 22.
Все это возможно только благодаря инвестициям Google в свою систему сборки. Конечно, Google уникальна с точки зрения масштаба, однако любая организация любого размера может получить аналогичные преимущества, включив в свой производственный процесс современную систему сборки. В этой главе мы выясним, какие системы сборки считаются в Google «современными» и как их использовать.
Так ли необходимы системы сборки?
Системы сборки позволяют масштабировать разработку. Как будет показано в следующем разделе, отсутствие надлежащей системы сборки порождает проблемы масштабирования.
Мне достаточно компилятора!
Потребность в системе сборки может быть неочевидна. В конце концов, едва ли кто-то из нас использовал систему сборки, когда учился программированию — почти все мы начинали с таких инструментов командной строки, как gcc или javac, или их эквивалентов в IDE. Пока весь исходный код располагается в одном каталоге, вполне можно использовать такую команду:
javac *.javaОна предписывает компилятору Java взять каждый файл с исходным кодом на Java в текущем каталоге и преобразовать его в двоичный файл класса. В простейшем случае этого более чем достаточно.
Однако ситуация быстро усложняется с увеличением размеров проекта. Компилятор javac может найти импортируемый код в подкаталогах, находящихся в текущем каталоге, но он не умеет искать код, хранящийся в других местах файловой системы (например, в библиотеке, совместно используемой несколькими проектами). Кроме того, он может преобразовывать код только на Java. Поскольку разные части больших систем часто пишутся на разных языках программирования, которые имеют множество зависимостей между собой, ни один компилятор для единственного языка не сможет собрать всю систему.
Как только приходится иметь дело с кодом на нескольких языках или с несколькими единицами компиляции, сборка кода превращается в многоэтапный процесс. В такой ситуации приходится задумываться, от чего зависит тот или иной код, и выполнять сборку частей в правильном порядке, возможно, с помощью разных инструментов для каждой части. Если изменится любая из частей, этот процесс придется повторить, чтобы избежать зависимости от устаревших двоичных файлов. Для кодовой базы даже среднего размера этот процесс быстро становится утомительным и подверженным ошибкам.
Компилятор также не знает, как обрабатывать внешние зависимости, например сторонние файлы JAR в Java. Часто лучшее, что можно сделать в отсутствие системы сборки, — загрузить зависимость из интернета, поместить ее в папку lib на жестком диске и настроить компилятор для чтения библиотек из этой папки. Однако со временем легко забыть, какие библиотеки туда помещены, откуда они взялись и используются ли они до сих пор. И останется надеяться только на удачу при их обновлении по мере выхода новых версий.
Сценарии командной оболочки спасут ситуацию?
Предположим, что ваш любительский проект изначально достаточно прост, чтобы собрать его с помощью компилятора, но постепенно в нем появляются вышеописанные проблемы. Возможно, вы все еще думаете, что вам не нужна настоящая система сборки и достаточно автоматизировать наиболее утомительные этапы сборки, написав несколько простых сценариев командной оболочки, которые позаботятся о сборке компонентов в правильном порядке. Это принесет облегчение на какой-то период, но довольно скоро вы начнете сталкиваться с еще более сложными проблемами:
- Поддержка сборки становится все более утомительной. По мере усложнения системы работа со сценариями начинает отнимать столько же времени, сколько работа с фактическим кодом. Отладка сценариев командной оболочки — трудная задача, все больше и больше нестандартных случаев начинают наслаиваться друг на друга.
- Сборка происходит медленно. Чтобы гарантировать актуальность всех зависимостей, вы запускаете сценарий, который собирает их по порядку при каждом запуске. Вы задумываетесь о добавлении логики для определения частей, которые действительно необходимо собрать повторно, но эта задача кажется ужасно сложной. Или, может быть, вы думаете о том, чтобы каждый раз указывать, какие части следует пересобрать, но это опять приводит вас в исходную точку.
- Хорошая новость: пора выпускать новую версию! Вы вспоминаете, какие аргументы нужно передать команде jar, чтобы выполнить окончательную сборку (https://xkcd.com/1168), как выгрузить результат и отправить в центральный репозиторий, как создать и разместить обновления в документации, как отправить пользователям уведомления. Хм-м, пожалуй, для этого нужно написать еще один сценарий…
- Катастрофа! Ваш жесткий диск выходит из строя, и теперь вам нужно воссоздать всю систему. Вы были достаточно предусмотрительны и хранили все файлы с исходным кодом в VCS, но как быть с библиотеками, загруженными из интернета? Сможете ли вы найти их снова и гарантировать соответствие версий? Ваши сценарии, вероятно, зависели от определенных инструментов, установленных в определенных местах, — сможете ли вы воссоздать идентичную среду, чтобы сценарии работали как раньше? А как быть с переменными окружения, которые вы настроили давным-давно, чтобы добиться правильной работы компилятора, а потом забыли о них?
- Несмотря ни на что, ваш проект достаточно успешен, и вы можете нанять еще нескольких инженеров. Теперь вы понимаете, что предыдущие проблемы еще не были катастрофой — теперь вам нужно снова и снова проходить один и тот же болезненный процесс настройки окружения для каждого нового разработчика. И несмотря на прилагаемые усилия, все системы разработчиков будут немного отличаться друг от друга. Часто то, что работает на одном компьютере, не работает на другом, и каждый раз требуется несколько часов, чтобы правильно настроить пути к инструментам или проверить версии библиотек, чтобы выяснить, в чем разница.
- Вы решаете автоматизировать систему сборки. Теоретически для этого достаточно поставить новый компьютер и настроить на нем запуск сценария сборки по ночам с помощью cron. Вам по-прежнему нужно пройти болезненный процесс настройки, но теперь у вас нет преимуществ человеческого мозга, способного обнаруживать и решать мелкие проблемы. Теперь, входя по утрам в систему, вы видите, что ночная сборка потерпела неудачу, потому что вчера разработчик внес изменение, которое работало в его системе, но не работает в системе автоматической сборки. Каждая такая проблема легко исправляется, но делать это приходится так часто, что каждый день вы тратите массу времени на поиск и применение простых исправлений.
- По мере развития проекта сборки выполняются все медленнее и медленнее. Однажды, ожидая завершения сборки, вы с грустью смотрите на пустующий рабочий стол коллеги, который находится в отпуске, и задумываетесь о возможности задействовать простаивающие вычислительные мощности.
Это проблема масштабирования. Для одного разработчика, работающего над парой сотен строк кода в течение одной-двух недель (типичный опыт младшего разработчика, только что окончившего университет), компилятора более чем достаточно. Сценарии помогут вам продвинуться немного дальше. Но как только вам потребуется координировать действия нескольких разработчиков и работу их компьютеров, даже идеального сценария сборки будет недостаточно, потому что очень трудно учесть незначительные различия между системами. На этом этапе нужно начинать инвестировать в систему сборки.
Современные системы сборки
К счастью, все описанные проблемы уже решены существующими универсальными системами сборки. По сути, они не сильно отличаются от вышеупомянутого подхода «сделай сам» на основе сценариев: они запускают те же самые компиляторы и требуют знания особенностей базовых инструментов. Но эти системы разрабатывались много лет, что сделало их гораздо более надежными и гибкими, чем сценарии, которые вы можете написать сами.
Все дело в зависимостях
Рассматривая проблемы, описанные выше, мы снова и снова наблюдали одну и ту же закономерность: намного легче управлять своим кодом, чем его зависимостями (глава 21). Зависимости могут быть самыми разнообразными: от задачи (например, «отправить документацию, прежде чем отметить выпуск завершенным») или от артефакта (например, «для сборки кода нужна последняя версия библиотеки компьютерного зрения»). Иногда ваш код может иметь внутренние зависимости от других частей кодовой базы или внешние зависимости от кода или данных, принадлежащих другим командам (в вашей или сторонней организации). Но в любом случае идея «мне нужно это, чтобы получить то» постоянно повторяется в системах сборки, и управление зависимостями, возможно, является их самой фундаментальной задачей.
Системы сборки на основе задач
Сценарии командной оболочки из предыдущего раздела были примером примитивной системы сборки на основе задач. Главной единицей работы такой системы является задача. Каждая задача — это своего рода сценарий, который может выполнять любую логику и зависеть от других (заранее выполненных) задач. Большинство современных систем сборки, таких как Ant, Maven, Gradle, Grunt и Rake, основаны на задачах.
Большинство современных систем сборки требуют, чтобы вместо сценариев командной оболочки инженеры создавали файлы сборки, описывающие порядок сборки. Вот пример из руководства Ant (https://oreil.ly/WL9ry):
<project name="MyProject" default="dist" basedir=".">
<description>
простой файл сборки
</description>
<!-- глобальные параметры для этой сборки -->
<property name="src" location="src"/>
<property name="build" location="build"/>
<property name="dist" location="dist"/>
<target name="init">
<!-- Создать отметку времени -->
<tstamp/>
<!-- Создать структуру каталогов сборки для компилятора -->
<mkdir dir="${build}"/>
</target>
<target name="compile" depends="init"
description="компиляция ресурсов">
<!-- Скомпилировать код на Java из ${src} в ${build} -->
<javac srcdir="${src}" destdir="${build}"/>
</target>
<target name="dist" depends="compile"
description="создание дистрибутива">
<!-- Создать каталог для дистрибутива -->
<mkdir dir="${dist}/lib"/>
<!-- Поместить все артефакты из ${build} в файл MyProject-${DSTAMP}.jar -->
<jar jarfile="${dist}/lib/MyProject-${DSTAMP}.jar" basedir="${build}"/>
</target>
<target name="clean"
description="очистка">
<!-- Удалить каталоги ${build} и ${dist} -->
<delete dir="${build}"/>
<delete dir="${dist}"/>
</target>
</project>Файл сборки написан на XML и определяет простые метаданные о сборке и задачи (теги в XML1). Каждая задача выполняет список команд, поддерживаемых системой Ant, включая создание и удаление каталогов, запуск javac и создание файла JAR. Набор команд можно расширить с помощью подключаемых модулей (плагинов), чтобы охватить любую логику. Каждая задача может также определять задачи, от которых она зависит, перечислив их в атрибуте depends. Эти зависимости образуют ациклический граф (рис. 18.1).
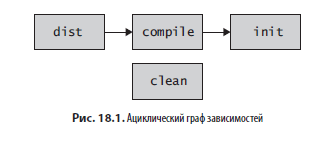
Пользователи выполняют сборку, вызывая инструмент командной строки Ant и передавая ему задачи в аргументах. Например, когда пользователь запускает команду ant dist, система сборки Ant выполняет следующие шаги:
- Загружает файл build.xml в текущий каталог и анализирует его, чтобы создать граф (рис. 18.1).
- Отыскивает задачу с именем dist, указанную в командной строке, и обнаруживает, что она зависит от задачи с именем compile.
- Отыскивает задачу compile и обнаруживает, что она зависит от задачи init.
- Отыскивает задачу init и обнаруживает, что она не имеет зависимостей.
- Выполняет команды, перечисленные в задаче init.
- Выполняет команды, перечисленные в задаче compile, после выполнения всех зависимостей этой задачи.
- Выполняет команды, перечисленные в задаче dist, после выполнения всех зависимостей этой задачи.
В итоге код, выполняемый системой Ant при запуске задачи dist, эквивалентен следующему сценарию командной оболочки:
./createTimestamp.sh
mkdir build/
javac src/* -d build/
mkdir -p dist/lib/
jar cf dist/lib/MyProject-$(date --iso-8601).jar build/*Если убрать синтаксис, то файл сборки мало чем отличается от сценария сборки. Тем не менее мы уже многого добились. Теперь мы можем создавать новые файлы сборки в других каталогах, связывать их друг с другом и добавлять новые задачи, зависящие от имеющихся. Нам достаточно только передать имя одной задачи инструменту командной строки ant, и он позаботится обо всем остальном.
Ant — это очень старая система. Первая ее версия была выпущенная в 2000 году и была совсем не похожа на «современную» систему сборки! За прошедшие годы появились другие системы, такие как Maven и Gradle, по сути заменившие Ant. Они добавили такие возможности, как автоматическое управление внешними зависимостями и более ясный синтаксис без XML. Но природа этих новых систем осталась прежней: они позволяют инженерам писать сценарии сборки принципиальным и модульным способом в виде перечней задач и предоставляют инструменты для их выполнения и управления зависимостями.
Темная сторона систем сборки, основанных на задачах
По сути, эти системы позволяют инженерам определить любой сценарий как задачу и реализовать практически все, что только можно вообразить. Но работать с ними становится все труднее с увеличением сложности сценариев сборки. Проблема таких систем состоит в том, что они многое перекладывают на плечи инженеров, почти ничего не делая самостоятельно. Система не знает, что делают сценарии, и из-за этого страдает производительность, потому что система вынуждена действовать максимально консервативно, планируя и выполняя этапы сборки. Кроме того, система не может убедиться, что каждый сценарий выполняет то, что должен, поэтому сценарии усложняются и требуют отладки.
Сложность параллельного выполнения этапов сборки. Современные рабочие станции, используемые для разработки, обычно обладают большой вычислительной мощностью, имеют процессоры с несколькими ядрами и теоретически способны выполнять несколько этапов сборки параллельно. Но системы на основе задач часто не могут выполнять задачи параллельно, даже если это выглядит возможным. Предположим, что задача A зависит от задач B и C. Поскольку задачи B и C не зависят друг от друга, безопасно ли выполнять их одновременно, чтобы система могла быстрее перейти к задаче A? Возможно, если они не используют одни и те же ресурсы. Но если они используют один и тот же файл для хранения статуса выполнения, то их одновременный запуск вызовет конфликт. В общем случае система ничего не знает об этом, поэтому она должна рисковать вероятностью конфликтов (которые могут приводить к редким, но очень трудным для отладки проблемам сборки) или ограничиться выполнением сборки в одном потоке и в одном процессе. Из-за этого огромная вычислительная мощь машины разработчика может недоиспользоваться, возможность распределения сборки между несколькими машинами будет полностью исключена.
Сложности инкрементального выполнения сборки. Хорошая система сборки позволяет инженерам выполнять инкрементальные сборки, когда небольшое изменение не требует повторной сборки всей кодовой базы с нуля. Это особенно важно, если система сборки работает медленно и не может выполнять этапы сборки параллельно по вышеупомянутым причинам. Но, к сожалению, и здесь системы сборки, основанные на задачах, показывают себя не с лучшей стороны. Поскольку задачи могут делать что угодно, невозможно проверить, были ли они уже выполнены. Многие задачи просто берут набор исходных файлов и запускают компилятор, чтобы создать набор двоичных файлов, поэтому их не нужно запускать повторно, если исходные файлы не изменились. Но, не имея дополнительной информации, система не может знать, загружает ли задача файл, который был изменен, или записывает ли она отметку времени, изменяющуюся при каждом запуске. Чтобы гарантировать безошибочность, система часто вынуждена повторно запускать каждую задачу во время каждой сборки.
Некоторые системы сборки пытаются разрешить инкрементальные сборки, позволяя инженерам указывать условия, при которых задача должна быть повторно запущена. Эта возможность реализуется гораздо сложнее, чем кажется. Например, в таких языках, как C++, которые позволяют напрямую подключать другие файлы, невозможно определить весь набор файлов, за изменениями в которых необходимо следить, без анализа исходного кода. Инженеры строят догадки и нередко ошибочно используют результат задачи повторно. Когда такое случается слишком часто, у инженеров вырабатывается привычка запускать задачу чистки (clean) перед каждой сборкой, чтобы обновить состояние, что полностью лишает смысла инкрементальную сборку. На удивление сложно выяснить, когда задача должна выполняться повторно, и с этим машины справляются лучше, чем люди.
Сложности сопровождения и отладки сценариев. Наконец, сами сценарии сборки, используемые системами сборки на основе задач, часто слишком сложны для сопровождения. Им часто уделяется меньше внимания, но, тем не менее, сценарии сборки — это точно такой же код, как и собираемая система, и в них тоже могут появляться ошибки. Вот несколько примеров ошибок, которые очень часто допускаются при работе с системой сборки на основе задач:
- Задача A зависит от задачи B, ожидая получить от нее определенный файл. Владелец задачи B не понимает, что от нее зависят другие задачи, поэтому он меняет ее, и в результате файл, генерируемый задачей B, оказывается в другом месте. Эта ошибка никак не проявляет себя, пока кто-то не попытается запустить задачу A и не обнаружит, что она терпит неудачу.
- Задача A зависит от задачи B, которая зависит от задачи C, которая создает определенный файл, необходимый задаче A. Владелец задачи B решает, что она больше не должна зависеть от задачи C, что заставляет задачу A терпеть неудачу, потому что задача B больше не вызывает задачу C!
- Разработчик новой задачи делает ошибочное предположение о машине, на которой выполняется задача, например о местоположении инструмента или значениях определенных переменных окружения. Задача работает на его компьютере, но терпит неудачу на компьютере другого разработчика.
- Задача выполняет недетерминированную операцию, например загружает файл из интернета или добавляет отметку времени в сборку. Из-за этого разработчики получают потенциально разные результаты при каждом запуске сборки, а значит, не всегда могут воспроизвести и исправить ошибки, возникающие друг у друга или в автоматизированной системе сборки.
- Задачи с множественными зависимостями могут оказываться в состоянии гонки. Если задача A зависит от задач B и C, а задачи B и C изменяют один и тот же файл, то задача A будет получать разный результат, в зависимости от того, какая из задач — B или C — завершится первой.
Нет универсального рецепта решения этих проблем производительности, безошибочности или удобства сопровождения в рамках описанной здесь структуры задач. Пока инженеры пишут произвольный код для выполнения во время сборки, у системы не будет достаточно информации, чтобы всегда быстро и безошибочно производить сборку. Чтобы решить эту проблему, нужно отобрать часть полномочий у инженеров и передать их системе, а также переосмыслить роль системы, но уже не в терминах выполняемых задач, а в терминах создаваемых артефактов. Этот подход используется в Blaze, и Bazel и описывается в следующем разделе.
Более подробно с книгой можно ознакомиться на сайте издательства
Оглавление книги «Делай как в Google. Разработка программного обеспечения»
 Оглавление книги «Делай как в Google. Разработка программного обеспечения»
Оглавление книги «Делай как в Google. Разработка программного обеспечения»








Для читателей bookflow скидка 25% по купону — Google
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.








 на 100 слоях")




