
Каждый современный сайт содержит файлы и папки, на которые не ведут никакие ссылки. Среди них могут попадаться весьма интересные, например, забытые резервные копии базы данных или сайта, phpMyAdmin, входы в административные панели и другие страницы, не предназначенные для всеобщего доступа.
Ниже мы расскажем, как пользоваться программой lulzbuster для поиска файлов и папок. Поехали.
Описание lulzbuster
Очень быстрый и умный инструмент для перебора веб директорий и файлов написан на C. Используется для поиска скрытых папок и файлов, на которые отсутствуют ссылки.
С одной стороны, lulzbuster очень прост в использовании, но при этом имеет много настроек и дополнительных возможностей.
Домашняя страница: https://nullsecurity.net/tools/scanner.html
Справка по lulzbuster
Использование:
lulzbuster -s <АРГУМЕНТ> [ОПЦИИ] | <ПРОЧЕЕ>
Опции:
опции указания цели
-s <url> - начальный url с которого начнётся сканирование
опции http
-h <тип> - тип http запроса (по умолчанию: GET) - ? для вывода списка типов
-x <код> - исключить их показа коды статуса http (по умолчанию: 400,404,500,501,502,503
несколько кодов разделяются ',')
-f - следовать http перенаправлениям. Подсказка: лучше попробуйте добавить '/'
с опцией '-A' вместо использование '-f'
-F <число> - число уровней следования http редиректам (по умолчанию: 0)
-u <строка> - строка user-agent (по умолчанию: встроенные windows firefox)
-U - использовать случайный user-agents из встроенных
-c <строка> - передать указанный заголовок или несколько заголовков (например, 'Cookie: foo=bar; lol=lulz')
-a <creds> - учётные данные http аутентификации (формат: <пользователь>:<пароль>)
-r - включить автоматическое обновление реферера
-j <число> - указать версию http (по умолчанию: дефолтная версия curl default) - ? для вывода всех
опции таймаута
-D <число> - количество секунд для задержки между запросами (по умолчанию: 0)
-C <число> - количество секунд для таймаута соединения (по умолчанию: 10)
-R <число> - количество секунд для таймаута запроса (по умолчанию: 30)
-T <число> - количество секунд перед признанием поражения и полного выхода из lulzbuster
(по умолчанию: нет)
опции тонкой подстройки
-t <число> - число потоков для одновременного сканирования (по умолчанию: 30)
-g <число> - размер кэша подключений для curl (по умолчанию: 30)
Примечание: это значение всегда должно быть равным значению, указанному с опцией -t
другие опции
-w <файл> - файл словаря
(по умолчанию: /usr/share/lulzbuster/lists/medium.txt)
-A <строка> - добавить любые слова, разделённые запятой (например, '/,.php,~bak)
-p <адрес> - адрес прокси (формат: <схема>://<хост>:<порт>) - ? для
вывода списка всех поддерживаемых схем
-P <creds> - учётные данные проверки подлинности на прокси (формат: <пользователь>:<пароль>)
-i - небезопасный режим (пропустить проверку сертификата ssl/tls)
-S - умный режим aka пропуск ложных срабатываний, больше информации,
и т.д. (используйте это если скорость не является вашим первым приоритетом!)
-n <строка> - сервера имён (по умолчанию: '1.1.1.1,8.8.8.8,208.67.222.222'
если несколько, то разделяются запятыми '.')
-l <файл> - сохранить найденные пути и действительные url в файл журнала
прочее
-X - вывести список встроенных user-agents
-V - вывести версию lulzbuster и выйти
-H - вывести справку и выйти
Примеры запуска lulzbuster
Поиск на сайте (-s https://failsame.ru/) скрытых файлов и папок с использованием большого словаря (-w /usr/share/lulzbuster/lists/big.txt):
lulzbuster -s https://failsame.ru/ -w /usr/share/lulzbuster/lists/big.txt
Установка lulzbuster
Установка в Kali Linux
sudo apt install libcurl4 libcurl4-openssl-dev git clone https://github.com/noptrix/lulzbuster cd lulzbuster make lulzbuster sudo make install
Установка в BlackArch
Программа предустановлена в BlackArch.
sudo pacman -S lulzbuster
Скриншоты lulzbuster
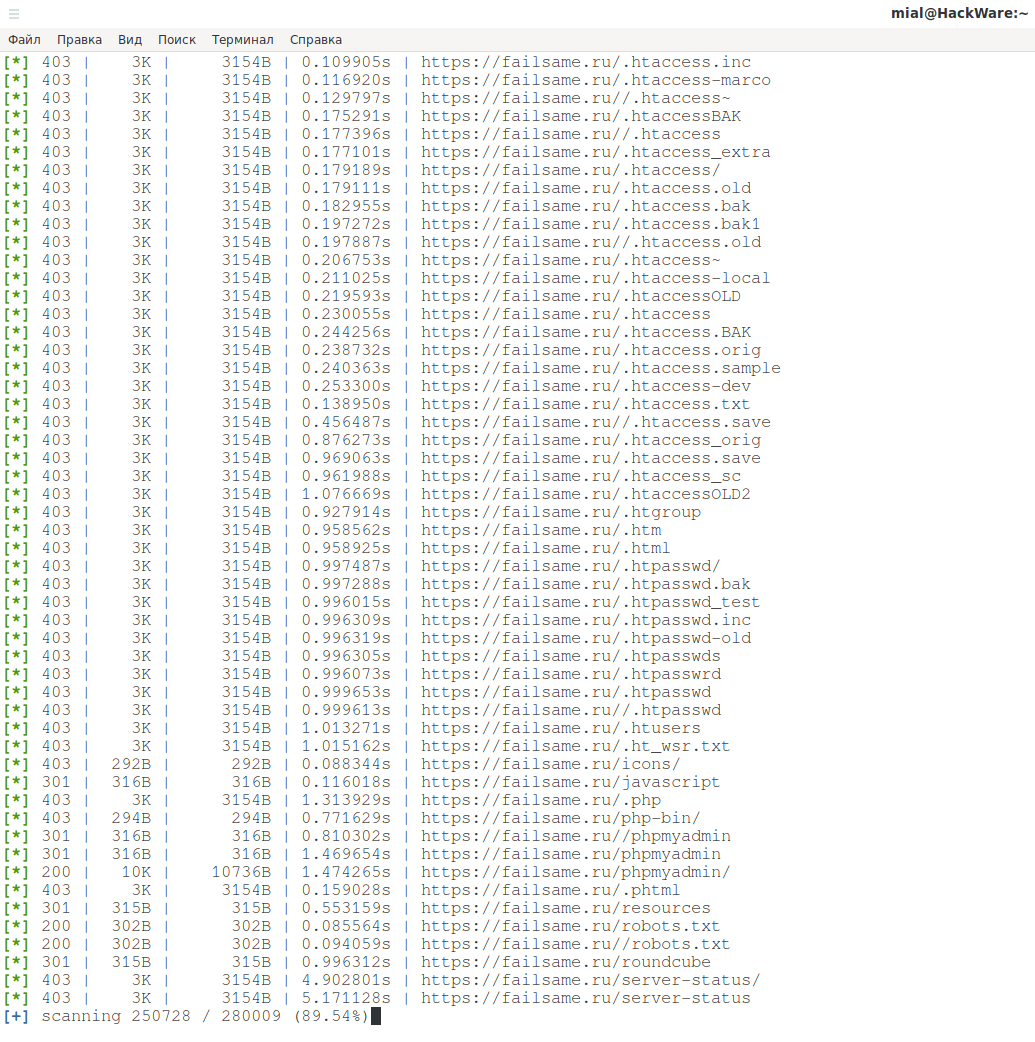
Как запустить поиск скрытых файлов в lulzbuster
Обратите внимание: программа делает много запросов к сайту и может стать причиной сбоя в его работе (как это происходит при DoS атаке), поэтому чужие сайты сканируйте только с разрешения их владельца! Вас предупредили!!!
У программы только одна обязательная опция -s после которой нужно указать целевой сайт:
lulzbuster -s https://SITE.RU/
Причём сайт нужно указывать с протоколом, например:
lulzbuster -s https://file-mix.com/
Программа начнёт с вывода своих настроек — многие значения установлены по умолчанию, но их можно изменить опциями:
Затем программа начнёт выводить данные со следующими столбцами:
- code (HTTP код статуса ответа)
- size (размер полученных данных)
- real size (реальный размер)
- resp time (время ответа)
- url (адрес найденной страницы)
По умолчанию используется словарь среднего размера, а всего с программой поставляется три словаря:
- big.txt (большой)
- medium.txt (средний)
- small.txt (маленький)
В Kali Linux эти словари размещены в следующих файлах:
- /usr/local/share/lulzbuster/lists/big.txt
- /usr/local/share/lulzbuster/lists/medium.txt
- /usr/local/share/lulzbuster/lists/small.txt
Для выбора любого из этих словарей, либо своего собственного, используйте опцию -w, например:
lulzbuster -s https://file-mix.com/ -w /usr/local/share/lulzbuster/listsbig.txt
Как исключить ответы с определёнными кодами статуса
По умолчанию не показываются ссылки, которые вернули следующие HTTP коды ответа: 400,404,500,501,502,503. Вы можете изменить этот список, добавив или удалив любые коды. Для этого используется опция -x, сами коды ответа нужно перечислять через запятую:
lulzbuster -s https://SITE.com/ -x 400,404,500,501,502,503,403,405
Как сохранить результаты lulzbuster в файл
По умолчанию lulzbuster выводит информацию в стандартный вывод ошибок (stderr). Вы можете указать файл для сохранения результатов опцией -l:
lulzbuster -s https://file-mix.com/ -w /usr/local/share/lulzbuster/lists/small.txt -l ~/file-mix.com-url.txt
Обратите внимание, что лучше указывать абсолютный путь до файла, т. к. в противном случае файл будет сохранён относительно рабочей директории lulzbuster.
Как добавить расширение для сканируемых файлов
С помощью опции -A <СТРОКА> можно добавить любые слова, разделённые запятой (например, /,.php,~bak).
Как сканировать с lulzbuster через Tor
Если это ещё не сделано, установите и запустите службу Tor:
sudo apt install tor
sudo systemctl start tor
Теперь к вашей команде lulzbuster добавьте опцию -p socks5://localhost:9050, например:
lulzbuster -s https://file-mix.com/ -p socks5://localhost:9050
Помните, что некоторые сайты вовсе не принимают подключения с IP адресов сети Tor.
Как сканировать с lulzbuster через прокси
Поддерживается несколько видов прокси, чтобы увидеть доступные варианты выполните команду:
lulzbuster -p ?
Пример вывода:
[+] available proxy schemes
> http
> https
> socks4
> socks4a
> socks5
> socks5h
Для прокси используйте следующие опции:
-p <адрес> - адрес прокси (формат: <схема>://<хост>:<порт>)
-P <creds> - учётные данные проверки подлинности на прокси (формат: <пользователь>:<пароль>)
Как сканировать в lulzbuster если недействительный сертификат
Бывает, что сертификат просрочен, либо сканируется IP адрес, в этом случае веб-браузеры показывают предупреждение, а lulzbuster останавливает сканирование с ошибкой:
[-] could not connect to:
Чтобы выполнить сканирование даже несмотря на неверный сертификат, используйте опцию -i:
lulzbuster -s https://koronavirus.info/ -i
Умный режим lulzbuster
Умный режим, который заключается в пропуске ложных срабатываний, показывает больше информации и т. д., включается опцией -S:
lulzbuster -s https://file-mix.com/ -S
Используйте умный режим только если скорость не является вашим важным приоритетом!
Изменение User Agent в lulzbuster
В lulzbuster уже встроен большой список пользовательских агентов, чтобы вывести их список выполните команду:
lulzbuster -X
Вы можете указать любое значение User Agent с помощью опции -u <СТРОКА>.
Также вы можете использовать случайные User Agent из встроенных, для этого укажите опцию -U.
lulzbuster с http аутентификацией и передачей заголовков
Возможно выполнять сканирования с lulzbuster с HTTP аутентификацией или передачей HTTP заголовков (например, кукиз). Это можно сделать следующими
-c <строка> - передать указанный заголовок или несколько заголовков (например, 'Cookie: foo=bar; lol=lulz')
-a <creds> - учётные данные http аутентификации (формат: <пользователь>:<пароль>)
Скорость сканирования и таймаут lulzbuster
С помощью опции -t <ЧИСЛО> можно указать количество потоков, которыми будет выполняться сканирование.
Также доступны следующие опции таймаута:
-D <число> - количество секунд для задержки между запросами (по умолчанию: 0)
-C <число> - количество секунд для таймаута соединения (по умолчанию: 10)
-R <число> - количество секунд для таймаута запроса (по умолчанию: 30)
-T <число> - количество секунд перед признанием поражения и полного выхода из lulzbuster
(по умолчанию: нет)
Сканирование методами POST, HEAD, PUT, DELETE и другими
По умолчанию сканирование выполняется методом GET, но можно выбрать другой метод HTTP запросов.
Чтобы вывести список всех доступных методов выполните команду:
lulzbuster -h ?
Пример вывода:
[+] available HTTP requests types
> HEAD
> GET
> POST
> PUT
> DELETE
> OPTIONS
Желаемый тип HTTP запросов указывается опцией -h <ТИП>.
Как сканировать разными версиями HTTP
У протокола HTTP имеется несколько версий и можно выбрать ту, которую вы хотите использовать. Для этого задействуйте опцию -j <ЧИСЛО>.
Чтобы увидеть доступные версии HTTP выполните команду:
lulzbuster -j ?
Пример вывода:
[+] available http versions
> 1.0
> 1.1
> 2.0
> 3.0





")





 на 100 слоях")






