Формальная и интуитивная семантика языка программирования на примерах JS и JSX
Мотивацией к написанию этого материала послужила постоянная сложность, возникающая от чтения чужого кода, которая, должно быть, появляется у каждого. Какие-то конструкции кажутся избыточными или излишне сложными, какие-то вообще ошибочными. Иногда трудно понять, какую бизнес-задачу пытался решить автор и, в частности, какие особенности языка или стека ему в этом мешали. Даже собственный код спустя некоторое время становится малопонятным. Кажется, эта самая понятность исходит из контекстов: продукта, проекта, архитектуры и стека (фреймворки, библиотеки), команды и принятого кодстайла. С этим ничего не поделаешь, приходится вновь погружаться во все эти контексты и искать связи между ними — только тогда каждая конструкция в коде обрастает понятной мотивацией, страх перед неизвестностью проходит и желание всё переписать стихает.
Но бывает, можно натолкнуться на чужой, совершенно неизвестный код, который выглядит лаконичным и понятным. Сразу ясно, какую задачу он решает и как. Причем такой код может быть даже написан на другом языке программирования или с использованием неизвестного стека, но почему-то он нормально читается, интуитивно рассказывая свою историю.
Вот я и задался вопросом, есть ли всё же какие-то универсальные правила построения и структурирования кода, которые бы не зависели от конкретного языка программирования или стека? Я решил попробовать найти ответ, копнув в самую глубь, изучив, что такое язык программирования в общем и как с помощью этого понимания вывести правила лучших практик. Получилось поверхностное исследование, которое лишь приоткрыло всю глубину, сложность и историю вопроса, но в то же время чётко определило направление пути.
Декларативность
Многие называют «декларативное» программирование панацеей понятности и читаемости, но так ли это на самом деле? Почему кто-то с этим согласен на все 100%, а кто-то совершенно не разделяет энтузиазма? Нужно разобраться.
Все, наверное, слышали, чем декларативное программирование отличается от императивного: декларативное описывает, что нужно сделать, а императивное — как это нужно сделать. Но говоря об этом, обязательно стоит помнить, что при декларациях того, что нужно сделать, идет оперирование какими-то существующими элементами, о которых мы знаем, как они работают (иначе наши декларации ничего бы не стоили). Декларативное программирование — это способ описания программы через набор верхнеуровневых инструкций, детали реализации и исполнения которых скрыты за исполнителем этих инструкций. Под исполнителем могут подразумеваться: функции высшего порядка (ramda, react, redux-saga), макросы (JSX) в случае кодогенерации, JIT компилятор в случае исполнения (синтаксис ЯП — языка программирования), машинные коды — декларативное описание логики переключения транзисторов процессора. Т.е. средство описания деклараций всегда имеет какой-то контекст, и «декларативность» означает не какой-то конкретный паттерн, а текущий уровень восприятия глубины абстракции разработчиком.
Например, классическим примером декларативного программирования является код в функциональном стиле:
array.filter(predicate)
А что можно сказать про такой код?
instruction = { type: 'filter', target: array, arguments: [predicate] }
Он более декларативен — в нём нет прямого вызова функций, а только описание того, что нужно сделать. Как такое может быть, есть градации декларативности? А лучше ли этот код в плане читаемости и понимаемости? Кажется, ответ не совсем однозначный.
Так же можно рассмотреть классический «императивный» код:
for (let i = 0; i < array.length; i++) {
if (predicate(array[i])) result.push(array[i])
}
Он кажется более сложным, чем приведённые сниппеты выше, но если посмотреть на результирующий машинный код, то код с for и if покажется вполне простым и декларативным, т.к. он скрывает то, как работать с памятью на системном уровне.
Из всего этого можно сделать простой вывод: декларативность — это термин для определения уровня абстракции, который для каждого человека может быть разным в зависимости от контекста.
Как-то на ревью PR на работе я увидел чрезмерно «функциональный» подход в написании определённого набора действий и попробовал переписать этот код на «императивщину». Детали кода не важны, с первого взгляда видно, что «императивный» код (снизу) короче и в нём лучше выделены смысловые конструкции за счет их подсветки, а ещё он производительнее.
export const validateFormFields = state => {
const displayedFields = selectFormFieldsNames(state)
.map(name => selectFormField(state, name))
.filter(isSystem);
const arrayFields = displayedFields.filter(isArray);
const emptyRequiredArraysErrors = arrayFields
.filter(field => isArrayEmpty(field) && field.required)
.map(field => selectFriendlyText(state, field.title, field.name));
const arrayCellsErrors = arrayFields
.filter(field => !isArrayEmpty(field) && isTable(field))
.reduce((acc, field) => [...acc, ...validateArrayCells(state, field)], []);
const notArrayFields = displayedFields.filter(field => !isArray(field));
const notArrayFieldsErrors = notArrayFields
.filter(field => field.required && isValueExist(field.value))
.map(field => selectFriendlyText(state, field.title, field.name));
return [
...notArrayFieldsErrors,
...emptyRequiredArraysErrors,
...arrayCellsErrors
];
};
VS
function validateFormFields(state) {
const fieldsNames = selectFormFieldsNames(state);
const result = [];
for (let i = 0; i < fieldsNames.length; i++) {
const field = selectFormField(state, fieldsNames[i]);
if (isSystem(field)) continue;
if (!isArray(field) && field.required && isValueExist(field.value))
result.push(selectFriendlyText(state, field.title, field.name));
if (!isArray(field)) continue;
if (isArrayEmpty(field) && field.required)
result.push(selectFriendlyText(state, field.title, field.name));
if (!isArrayEmpty(field) && isTable(field))
result.push(...validateArrayCells(state, field));
}
return result;
}
При этом многие коллеги высказывались, что функциональный код им нравится больше и стоит использовать его. Тогда я устроил голосование в чате. Как же было забавно наблюдать, как мнение делится поровну, и кому-то понятнее функциональный подход, а кому-то императивный:
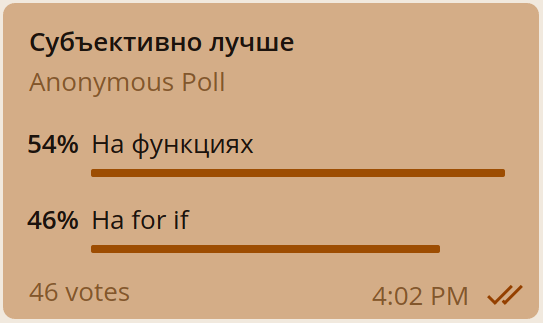
За функциональный подход высказалось больше людей, и многие из них — разработчики с богатым опытом. Хотелось им доверять, но при этом результаты голосования показали, что не всё так однозначно. В действительности те, кто имел опыт и привык работать с библиотеками в функциональном стиле, просто привыкли к такому паттерну и образу мышления, но это не означает, что он является единственно верным.
И функциональный, и императивный код решают одну и ту же задачу и дают один и тот же результат, но совершенно по-разному читаются, воспринимаются и даже исполняются в JIT. Проще говоря, эти два кода имеют разную семантику.
P.S. Код был в итоге переписан в функциональном стиле, но с вынесением определенной логики в отдельные функции.
Семантика
В изучении проблематики вопроса у меня не сразу получилось сформулировать о чём, с формальной точки зрения, вообще идет речь, есть ли для этого термин? Конечно, я не первый задавался вопросами читаемости и явности кода, и на этот счёт есть немало трудов. Но большинство ответов из первых страниц поисковых запросов и популярных книг по программированию выдавали перечень прикладных советов, часть из которых могут быть реализованы только в некоторых языках (зависят от синтаксиса). Хотелось найти первопричину, а к ней простое и универсальное элегантное решение, в котором не было бы противоречий. Например, следуя классическим советам, проектируя переиспользуемые компоненты, очень сложно избежать «зацепленности». И наоборот, при упрощении абстракций в коде снижается портированность и переиспользование его частей (повышается связанность), код повторяется. Особенно критично это может проявиться в долгосрочной перспективе, когда внесение изменений нужно синхронизировать между всеми одинаковыми участками кода.
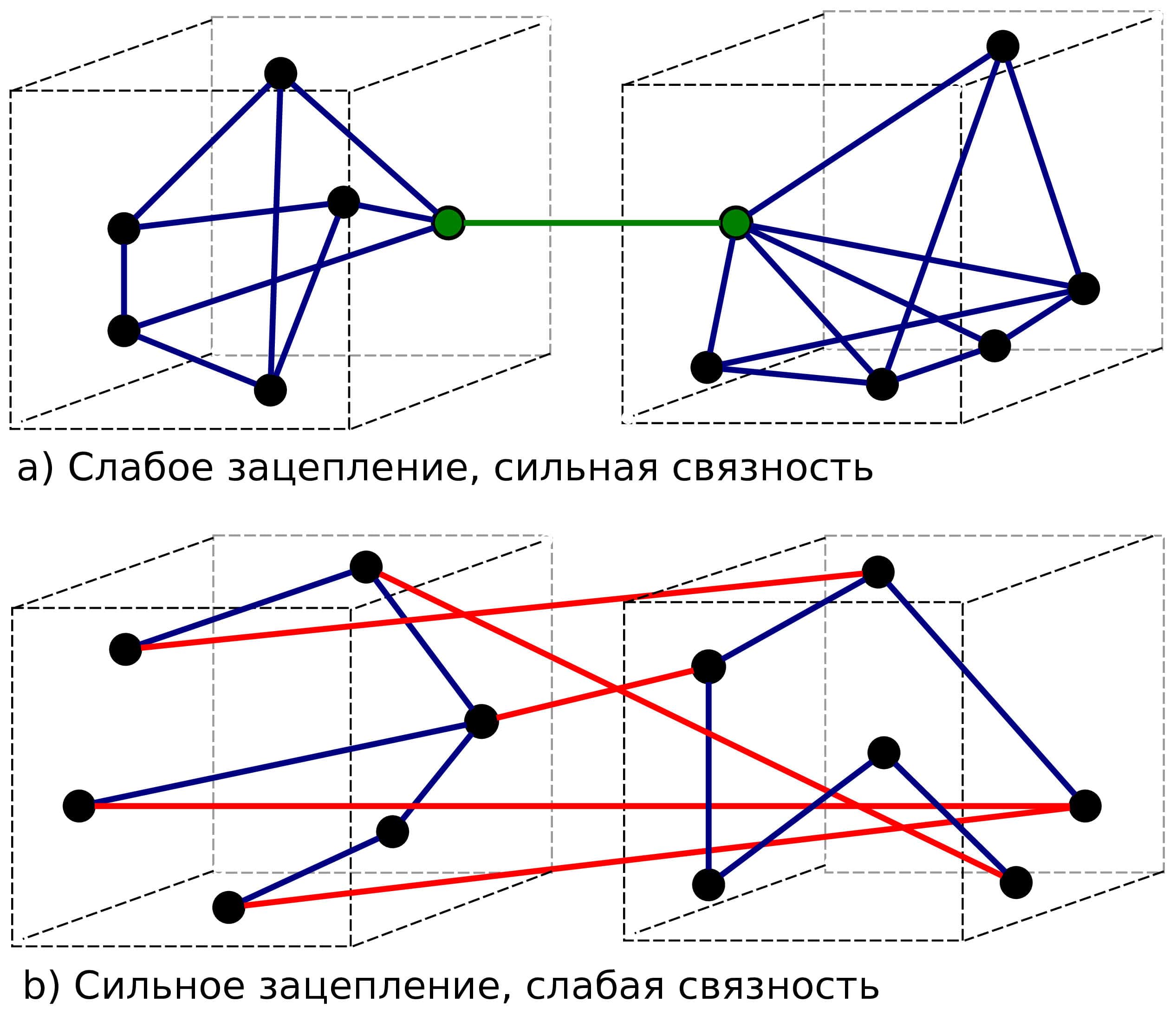
Явность кода — это не про code style в плане визуального форматирования и именования переменных. Явность кода зависит от множества контекстов — это про микро и макро архитектуру всего приложения и принятых стандартов написания кода. Можно ли обобщить? И тут я подумал: что объединяет все языки программирования? То, что это языки программирования.
Язык в общем и язык программирования в частности — это синтаксис и семантика. Две ключевых составляющих, которые определяют, что такое язык, как им пользоваться и выражать на нём свои мысли. И если с синтаксисом всё более менее понятно, то что такое семантика можно долго и упорно (не) понимать, хотя я догадывался, что все ответы на вопросы явности кода — в ней.
Вообще язык сам по себе — это сложная комплексная сущность, формализованные части которой также сложно понять. Википедия говорит:
Си́нтаксис (др.-греч. σύν-ταξις — составление) — раздел лингвистики, изучающий строение и функциональное взаимодействие различных частей речи в предложениях, словосочетаниях и пр. языковых единицах.
Сема́нтика (от др.-греч. σημαντικός «обозначающий») — раздел лингвистики, изучающий смысловое значение единиц языка.
Семантика отвечает за смысловое значение — ясность выражения мысли.
Ну вот определения, ну вот они что-то описывают — но что это в действительности значит, и как это можно использовать? Всё понимается проще на аналогиях, и можно попытаться найти их для определения синтаксиса и семантики применительно к ЯП. Мне нравится такая: если синтаксис — это какой-то инструмент, то семантика — это правила пользования инструментом.

Если попробовать детально разобраться в семантике как составляющей ЯП, то можно прийти к истории, общей теории языков программирования и, в частности, области компиляторов и формальному (математическому) доказательству корректности программ. На этот счёт есть хорошая вводная лекция университетского курса «Языки программирования и компиляторы». Я кратко перескажу ее.
Эволюция ЯП в улучшении абстракций: машинные коды, переменные (ассемблер), процедуры и условные переходы (Фортран), структуры (Алгол 68, Паскаль), ООП, функции высшего порядка и развитые системы типов. Сейчас мы, программисты, пользуемся этим, зачастую не задумываясь, как работают языки высокого уровня, какая история за ними стоит и почему они именно такие, какие есть. Но интересно, что сам принцип ЭВМ в процессе развития языков не менялся.
Вычислительная машина — это большой конечный автомат, точнее, конечный преобразователь (трансдьюсер). Её инструкции — набор переходов. Человеку сложно оперировать такими понятиями, особенно в большой программе, он в принципе мыслит иначе и для быстрого понимания чего-то часто применяет интуицию и абстракции, обобщая логику описания поведения (программы). Мостом же между инструкциями для вычислительной машины и человеком выступает интерфейс, который называется языком программирования. Вообще при написании кода и выражении задачи в виде набора операторов всё, что происходит — это перебор возможных вариантов работы с возможными данными, попытка описать строго формальным языком какую-то абстракцию — бизнес-задачу. И этот процесс (и код, в частности) очень похож на формальное математическое доказательство — бескомпромиссное, чёткое выведение верного решения. Эта похожесть называется «Соответствие Карри — Ховарда». Но отличие математического доказательства от написания программы заключается в том, что логика построения программы в первую очередь строится не на формальных доказательствах, а на интуитивных умозаключениях программиста, которые он уже пытается наложить на формальные правила ЯП. Потому что каждую задачу можно описать по-разному. Это, в частности, зависит и от личного представления программиста о задаче, от его привычек и способа мышления, знаний и умения использовать то или иное API языка, библиотек, фреймворков. Но как соотнести абстрактное представление программиста о задаче с чётким и формальным алгоритмом, можно ли формализовать это соотношение? Есть ли какое-то правило, функция, которая описывает и представляет разницу между индивидуальным кодом программиста и формальным необходимым результатом? Вот это как раз и называется семантика.
Синтаксис — для парсинга AST и построения структуры программы
Семантика — для понимания программы компилятором и интерпретатором
В итоге: семантика позволяет конкретизировать до формального уровня интуитивное представление кода программы. Иначе говоря, с первого взгляда код может иметь одну логику поведения, но, учитывая семантику, можно «увидеть» дополнительные аспекты/ветвления алгоритма и за счёт этого проверить программу на наличие ошибок. Я это понял именно так и для себя разделил семантику на две части: формальную и неформальную, или интуитивную. Формальная семантика — это чёткое представление кода программы в инструкции, она описывается спецификацией языка и используется компилятором или линтером для логического анализа кода и ошибок в нём. Интуитивная семантика — это примерное представление программиста о логике, которую воплощает код программы, она менее формализована, но проще понимается человеком.
Прикладные примеры
null VS undefined
null — это намеренно пустое значение, undefined — это неопределённое значение или, актуально для JS, неожиданно пустое значение.
С интуитивной точки зрения и null, и undefined означают пустое значение и имеют одно и тоже поведение, но с точки зрения формальной семантики это разные конструкции, что проявляется в мелочах. Например, если выражение obj.prop === null верно, можно быть уверенным, что свойство prop есть в объекте, но его значение пусто. Но если выражение obj.prop === undefined верно, то нет никаких гарантий, что свойство prop вообще есть в объекте, из этого ясно лишь то, что значение этого свойства отсутствует. И это наглядный пример, когда интуитивная и формальная семантика разные: первая рассказывает о проверке свойства и значения в объекте, вторая проверяет только значение. Для тех, кто работает с JS давно, это может быть очевидным, но в общем и целом, если я пишу код, в котором есть обращение к свойству, я ожидаю работу со значением этого свойства и не ожидаю, что этого свойства может не быть вовсе. Для проверки наличия свойства я буду использовать оператор in или метод hasOwnProperty — это более явно говорит о том, что делает код.
Код, в котором интуитивная и формальная семантика могут отличаться, тяжелее читать и отлаживать, потому что для его понимания нужно прогонять в мозгу всю спецификацию ЯП, касающуюся используемых конструкций.
Cсылочная прозрачность
// [1] setTimeout(f, time, prop) // [2] setTimeout(() => f(prop), time)
Два небольших сниппета кода, приведённых выше, с точки зрения интуитивной семантики, постановки задачи, одинаковые — нужно через какое-то время выполнить колбэк f. Однако фактически они различаются, и интересно, на что это может повлиять. Строго говоря, у второго варианта отсутствует ссылочная прозрачность: колбэк, который будет выполнен, зависит от переменной prop, которая может быть изменена после инициализации таймаута, но до выполнения колбэка. В первом варианте это невозможно, т.к. аргумент передаётся по ссылке, а не через переменную замыкания. Это очень хороший пример того, как различия в интуитивной и формальной семантике могут ненамеренно привести к неожиданному поведению и ошибке.
Тонкости спецификации
// [1]
console.log({ '2': null, ...({ '1': null, '2': null }) })
// [2]
console.log({ '2.0': null, ...({ '1.0': null, '2.0': null }) })
С первого взгляда может показаться, что это очень похожий код, результаты которого тоже будет похожи. Но, согласно спецификации, сортировка свойств объекта имеет некоторые особенности, поэтому в первом случае результат будет {1: null, 2: null}, а во втором {2.0: null, 1.0: null} — первыми свойствами всегда идут валидные индексы. Как можно заметить, во втором варианте порядок свойств поменялся. Эта логика не интуитивна и описывается в дебрях спецификации ЯП — формальной семантикой.
Паттерн «заместитель»
// [1]
function include(array, target) {
for (let i = 0; i < array.length; i++) {
if (array[i] === target) return true;
}
return false;
}
// [2]
function include(array, target) {
for (const element of array) {
if (element === target) return true;
}
return false;
}
Вот ещё похожий код. Интересный вопрос: какая у него может быть разница в производительности и почему? Продвинутые знания ЯП о работе итераторов могут подсказать, что for of должен быть немного медленнее, но здесь скрывается ещё одна хитрая проблема.
Proxy, get и set реализуют паттерн «заместитель», при котором возможно перехватить обращение к свойствам целевого объекта для выполнения какой-то дополнительной логики. Проблема этого паттерна в том, что он воздействует на поведение программы, но это воздействие никак не отражается визуально. Т.е., говоря о формальной семантике: в этом паттерне она вообще никак не отображается, соответственно, не сходится с интуитивной семантикой.
Если сравнить код 1 и 2, то станет понятно, что с функциональной точки зрения разницы в нём нет, но если array будет обёрнут в прокси, то каждый вызов array[i] будет «утяжелён» перехватчиком, поэтому у этого, казалось бы, одинакового кода может быть заметная разница в производительности в пользу варианта с for of (там перехватчик отработает лишь один раз на Symbol.iterator).
Если в проекте используются прокси или геттеры и сеттеры, то в любой случайной точке кодовой базы никогда нельзя быть до конца уверенным, есть здесь они или нет. Это невидимый контекст, чтобы узнать о котором иногда, особенно в больших проектах, требуется исследовать большое количество связанного кода. Таким образом, приходится либо постоянно быть неуверенным в читаемом коде, либо производить его многочисленные инспекции. Решением проблемы может быть использование паттерна «декоратор» или любое явное использование контекста и зависимостей.
JSX vs JS
JSX должен быть в JS, а не JS в JSX. Top level синтаксис в файле — это JS, сам JSX пишется только между открывающим и закрывающим тегом, соответственно, там необходимо иметь минимум JS. Вот и весь простой принцип написания читабельного JSX.
<Component /> // babel -> React.createElement(Component, null)
JSX с точки зрения интуитивной семантики — вёрстка, он отвечает за то, что будет отображаться, а не как, потому что его задача именно в инкапсуляции логики document.createElement (формальной семантики). И на этом примере можно понять, что хорошая декларативность / метапрограммирование — это когда фактической разницы в результате работы кода с точки зрения интуитивной и формальной семантики нет. Но возвращаясь к JSX: он, как и результат самого HTML, всегда должен быть статичен, независимо от данных. В подтверждение этому выступает API хуков жизненного цикла в классах или хуков в функциональных компонентах — они описываются в JS, до блока с JSX, это наглядно.
import { Switch, Route, Redirect } from 'react-router'
<Switch>
<Route exact path="/" component={Home} />
<Route path="/about" component={About} />
<Redirect to="/" />
</Switch>
Например, react-router является примером очень плохого API, т.к. через компонент <Switch> он предлагает описывать логику зависимостей от данных прямо в JSX, более того, сам элемент превращается в управляющий блок. При этом классическая семантика полностью рушится, что ведет к ментальному усложнению чтения кода — в JSX может быть спрятана не только вёрстка, и его уже нужно читать вдумчивее, в голове нужно держать больше контекста. Правильнее в JS в начале блока функционального компонента или метода render описывать все зависимости, высчитывать их и потом в конечный возвращаемый JSX вставлять всё необходимое. Это и есть декларативное описание.
title = predicate ? 'first' : 'second';
return <span>{title}</span>
Желание описать роутинг или что угодно ещё (есть даже библиотека с компонентами <If>, <For>) декларативно — понятно, т.к. это кажется нагляднее и проще (хотя не всё так просто, потому что пониманиеАбстракции = время(документация)). Но нужно понимать, что декларативное описание не обязано иметь единственный синтаксис/шаблон. JSX — это декларативный синтаксис к описанию биндинга модели приложения на DOM, и это означает, что его не нужно использовать для декларативного описания конструкций, которые не относятся к DOM напрямую. Для написания декларативного кода можно использовать, например, библиотеку Ramda, писать макросы и много другое.
Также react-router нарушает принцип SSoT, если в приложении имеется глобальный стейт-менеджер. Из-за этого компоненты, использующие и роутер, и стор, часто имеют какие-то костыли или выступают мостом между двумя стейтами. Хорошим решением было бы использовать роутинг через глобальный стор.
{
render(){
return (
<div>
{this.renderHeader()}
{this.renderError()}
{this.renderList()}
</div>
)
}
}
Есть подход «рендерМетодов», который подразумевает вынесение каких-то логических частей JSX в отдельные методы. Но проблема заключается в том, что связанность такого кода сильно увеличена из-за разброса props и отсутствия этих методов в react-devtools (отображается просто портянка JSX, непонятно откуда взявшаяся).
{
render(){
return (
<div>
<Header />
<Error />
<List />
</div>
)
}
}
Чтобы избежать проблем с «рендерМетодами», достаточно вынести их тело в отдельные компоненты. При этом их проще будет отследить в react-devtools, а некоторые зависимости класса, которые получаются из контекста, скорее всего, получится перенести в новые дочерние компоненты и разгрузить таким образом связанность в родительском компоненте.
Это наглядный пример того, как, игнорируя заветы семантики, можно получить практические проблемы, которые решаются исправлением кода к семантической верности.
Render Props через children тоже подходит как явный пример антипаттерна семантики. Да, сам подход хорошо решает технические проблемы, но сильно ухудшает читаемость кода, нарушая принципы ответственности JSX. Решением может быть использование сведе’ния render-props.
Плохие советы по render-props дают даже на популярном ресурсе css-tricks:
const App = () => {
return (
<Wrapper link="https://jsonplaceholder.typicode.com/users">
{({ list, isLoading, error }) => (
<div>
<h2>Random Users</h2>
{error ? <p>{error.message}</p> : null}
{isLoading ? (
<h2>Loading...</h2>
) : (
<ul>{list.map(user => <li key={user.id}>{user.name}</li>)}</ul>
)}
</div>
)}
<Wrapper/>
);
}
Приведённый код выглядит как каша: JSX и JS сильно смешаны, очень сложно разобрать саму вёрстку.
Можно попробовать не использовать JSX для контейнеров. Интересно, что тогда код больше похож на использование хуков:
const App = () => {
return React.createElement(
Wrapper,
{ link: "https://jsonplaceholder.typicode.com/users" },
({ list, isLoading, error }) => {
const errorView = error && <p>{error.message}</p>
const listView = list.map(user => <li key={user.id}>{user.name}</li>)
const bodyView = isLoading ? <h2>Loading...</h2> : <ul>{listView}</ul>
return (
<div>
<h2>Random Users</h2>
{errorView}
{bodyView}
</div>
)
}
)
}
Во втором примере errorView и bodyView проще вынести в отдельные компоненты и уменьшить связанность.
Показательным примером важности семантики расстановки блоков кода являются новые хуки в React.js:
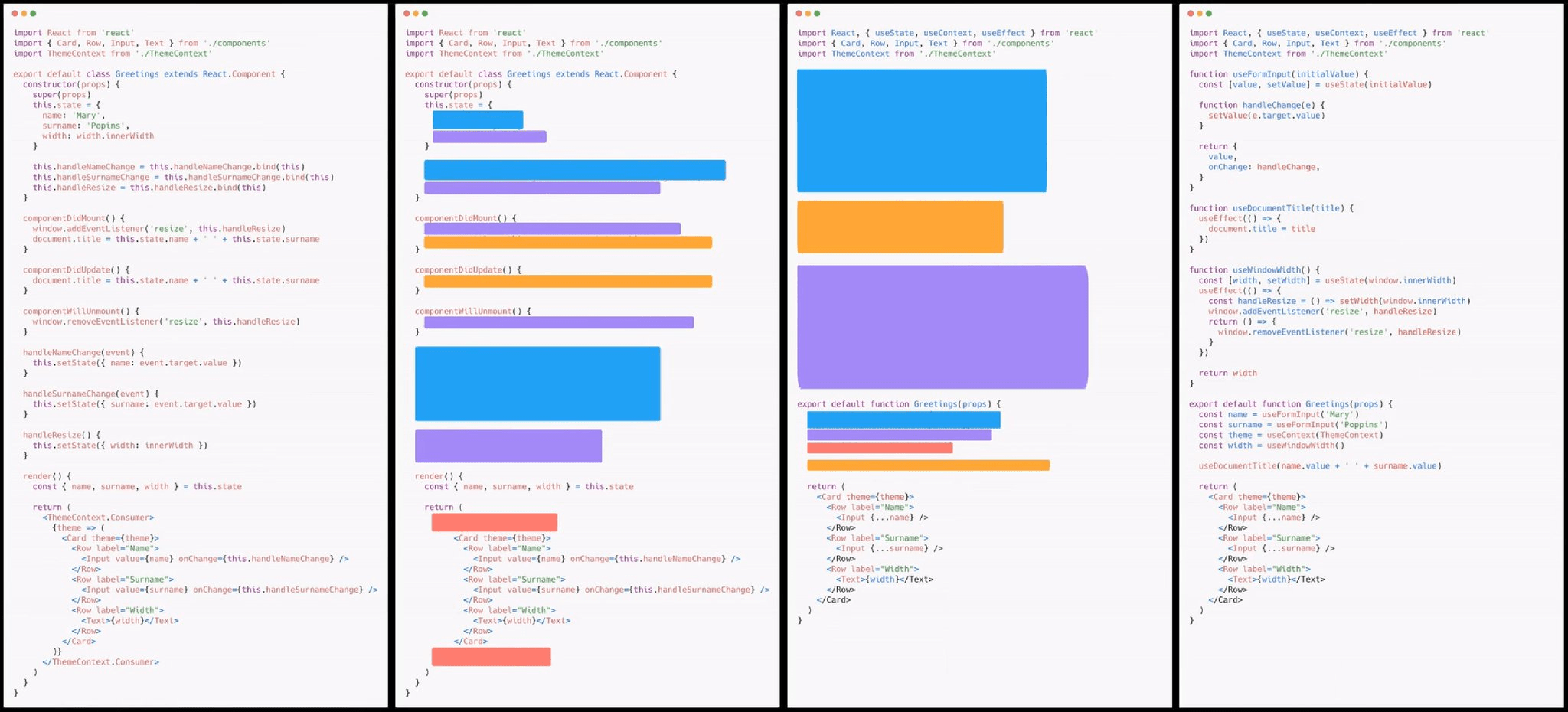
В этом примере код на классах был переписан на хуки, и, помимо сокращения количества строк, можно увидеть, что смысловые блоки сгруппировались. Благодаря этому понимать какие-то конкретные процессы, описанные кодом, стало проще. Т.е. интуитивную семантику можно повышать не только за счёт другого синтаксиса, но и за счёт правильной расстановки блоков кода. Идеальный баланс: сохранение одинаковой функциональности интуитивной и формальной семантики при минимальном количестве кода.
Вывод
Говоря обобщённо: за кодочитаемость отвечает семантика. В частности, под этим может подразумеваться множество аспектов языка: правильное использование типов данных и их особенностей, синтаксических конструкций, реализованных паттернов программирования (прокси), макросов и метапрограммирования и многое другое. Конечно, невозможно охватить такое многообразие перечнем небольших и конкретных правил, которые помогут писать исключительно идеальный код. Но общий вывод я мог бы сделать такой: явный код не содержит скрытых контекстов или скрытого поведения.
В читаемом и понятном коде нет разницы между интуитивной и формальной семантикой
На этом всё, но я буду продолжать исследовать семантику в ЯП и связанные с ней вещи в поисках универсальных правил явности и кодочитаемости.










 на 100 слоях")






