
Web-скрапинг с помощью C++ (cpp)
Веб-скрапинг — это распространенная техника сбора данных в Интернете, при которой клиент HTTP обрабатывает запрос пользователя на получение данных и использует парсер HTML для извлечения этой информации. Это помогает программистам более легко получать необходимую информацию для своих проектов.
Существует множество вариантов использования веб-скрапинга. Он позволяет получить доступ к данным, которые могут быть недоступны через API, а также к данным из нескольких разрозненных источников. С помощью этого метода можно собрать и проанализировать мнения пользователей о продукте, а также получить представление о состоянии рынка, например, о волатильности цен или проблемах дистрибуции. Однако собрать эти данные или интегрировать их в свои проекты не всегда было просто.
К счастью, веб-скрапинг стал более совершенным, и ряд языков программирования поддерживают его, включая C++. Этот популярный язык системного программирования также обладает рядом особенностей, которые делают его полезным для веб-скрапинга, например, скоростью, строгой статической типизацией и стандартной библиотекой, включающей в себя вывод типов, шаблоны для общего программирования, примитивы для параллелизма и лямбда-функции.
В этом руководстве вы узнаете, как использовать C++ для реализации веб-скрапинга с помощью библиотек libcurl и gumbo. Вы можете следить за развитием событий на GitHub.
Предварительные условия
Для этого урока вам понадобится следующее:
- базовое понимание HTTP
- C++ 11 или новее, установленный на вашей машине
- g++ 4.8.1 или новее
- библиотеки libcurl и gumbo C
- ресурс с данными для скрапинга (вы будете использовать сайт Merriam-Webster)
О веб-скрапинге
На каждый запрос HTTP, сделанный клиентом (например, браузером), сервер выдает ответ. И запросы, и ответы сопровождаются заголовками, которые описывают аспекты данных, которые клиент намерен получить, и объясняют все нюансы отправленных данных для сервера.
Например, допустим, вы сделали запрос на сайт Merriam-Webster для получения определений слова «эзотерический», используя cURL в качестве клиента:
GET /dictionary/esoteric HTTP/2 Host: www.merriam-webster.com user-agent: curl/7.68.0 accept: */*
Сайт Merriam-Webster будет отвечать заголовками, чтобы идентифицировать себя как сервер, HTTP-кодом ответа для обозначения успеха (200), форматом данных ответа — HTML в данном случае — в заголовке content-type, директивами кэширования и дополнительной метаданными CDN. Это может выглядеть примерно так:
HTTP/2 200 content-type: text/html; charset=UTF-8 date: Wed, 11 May 2022 11:16:20 GMT server: Apache cache-control: max-age=14400, public pragma: cache access-control-allow-origin: * vary: Accept-Encoding x-cache: Hit from cloudfront via: 1.1 5af4fdb44166a881c2f1b1a2415ddaf2.cloudfront.net (CloudFront) x-amz-cf-pop: NBO50-C1 x-amz-cf-id: HCbuiqXSALY6XbCvL8JhKErZFRBulZVhXAqusLqtfn-Jyq6ZoNHdrQ== age: 5787 <!DOCTYPE html> <html lang="en"> <head> <!--rest of it goes here-->
Вы должны получить аналогичные результаты после создания своего скрапера. Одна из двух библиотек, которые вы будете использовать в этом учебнике, — libcurl, на основе которой написан cURL.
Создание веб-скрапера
Скрапер, который вы собираетесь создать на C++, будет получать определения слов с сайта Merriam-Webster, избавляя вас от необходимости набирать текст, связанный с обычным поиском слов. Вместо этого вы сведете процесс к одному набору нажатий клавиш.
В этом руководстве вы будете работать в каталоге с именем scraper и с единственным одноименным файлом C++: scraper.cc.
Настройка библиотек
Две библиотеки на языке C, которые вы собираетесь использовать, libcurl и gumbo, работают здесь благодаря тому, что C++ хорошо взаимодействует с C. В то время как libcurl — это API, которое позволяет использовать несколько функций, связанных с URL и HTTP, и используется в клиенте с тем же именем, который был использован в предыдущем разделе, gumbo — это легковесный парсер HTML-5 с привязками к нескольким языкам, совместимым с С.
Использование vcpkg
Разработанный компанией Microsoft, vcpkg является кроссплатформенным менеджером пакетов для проектов C/C++. Следуйте этому руководству, чтобы настроить vcpkg на вашей машине. Вы можете установить libcurl и gumbo, набрав в консоли следующее:
$ vcpkg install curl $ vcpkg install gumbo
Если вы работаете в среде IDE, а именно в Visual Studio Code, выполните следующий фрагмент в корневом каталоге вашего проекта, чтобы интегрировать пакеты:
$ vcpkg integrate install
Использование apt
Если вы работали с Linux, вы должны быть знакомы с apt, которая позволяет удобно находить источники и управлять библиотеками, установленными в системе. Чтобы установить libcurl и gumbo с помощью apt, введите в консоль следующее:
$ sudo apt install libcurl4-openssl-dev libgumbo-dev
Установка библиотек
Вместо того чтобы выполнять установку вручную, вы можете воспользоваться методом, показанным ниже.
Сначала клонируйте репозиторий curl и установите его глобально:
$ git clone https://github.com/curl/curl.git <directory> $ cd <directory> $ autoreconf -fi $ ./configure $ make
Затем клонируйте репозиторий gumbo и установите пакет:
$ sudo apt install libtool $ git clone https://github.com/google/gumbo-parser.git <directory> $ cd <directory> $ ./autogen.sh $ ./configure $ make && sudo make install
Пишем парсер (скрапер)
Первым шагом в написании парсера является создание инструмента для выполнения HTTP-запроса. Артефакт — функция с названием request — позволит инструменту для скрапинга словаря получать разметку с сайта Merriam-Webster.
В функции request, определенной в файле scraper.cc, в приведенном ниже фрагменте кода, определены неизменяемые примитивы — имя клиента, которое идентифицирует скрапер через заголовок user-agent, и артефакты языка для записи разметки ответа сервера в память. Единственным параметром является слово, которое является частью пути URL, определения которого получает скрапер.
typedef size_t( * curl_write)(char * , size_t, size_t, std::string * );
std::string request(std::string word) {
CURLcode res_code = CURLE_FAILED_INIT;
CURL * curl = curl_easy_init();
std::string result;
std::string url = "https://www.merriam-webster.com/dictionary/" + word;
curl_global_init(CURL_GLOBAL_ALL);
if (curl) {
curl_easy_setopt(curl,
CURLOPT_WRITEFUNCTION,
static_cast < curl_write > ([](char * contents, size_t size,
size_t nmemb, std::string * data) -> size_t {
size_t new_size = size * nmemb;
if (data == NULL) {
return 0;
}
data -> append(contents, new_size);
return new_size;
}));
curl_easy_setopt(curl, CURLOPT_WRITEDATA, & result);
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_USERAGENT, "simple scraper");
res_code = curl_easy_perform(curl);
if (res_code != CURLE_OK) {
return curl_easy_strerror(res_code);
}
curl_easy_cleanup(curl);
}
curl_global_cleanup();
return result;
}
Не забудьте включить соответствующие заголовки в преамбулу вашего файла .cc или .cpp для библиотеки curl и библиотеки строк C++. Это позволит избежать проблем с компиляцией при подключении библиотек.
#include “curl/curl.h” #include “string”
Следующий шаг, разбор разметки, требует выполнения четырех функций: scrape, find_definitions, extract_text и str_replace. Поскольку gumbo занимает центральное место в разборе разметки, добавьте соответствующий заголовок библиотеки следующим образом:
#include “gumbo.h”
Функция scrape передает разметку из запроса в find_definitions для выборочного итеративного обхода DOM. В этой функции вы будете использовать парсер gumbo, который возвращает строку, содержащую список определений слов:
std::string scrape(std::string markup)
{
std::string res = "";
GumboOutput *output = gumbo_parse_with_options(&kGumboDefaultOptions, markup.data(), markup.length());
res += find_definitions(output->root);
gumbo_destroy_output(&kGumboDefaultOptions, output);
return res;
}
Функция find_definitions ниже рекурсивно собирает определения из элементов HTML span с уникальным идентификатором класса «dtText«. Она извлекает текст определения с помощью функции extract_text на каждой успешной итерации из каждого HTML-узла, в котором находится этот текст.
std::string find_definitions(GumboNode *node)
{
std::string res = "";
GumboAttribute *attr;
if (node->type != GUMBO_NODE_ELEMENT)
{
return res;
}
if ((attr = gumbo_get_attribute(&node->v.element.attributes, "class")) &&
strstr(attr->value, "dtText") != NULL)
{
res += extract_text(node);
res += "\n";
}
GumboVector *children = &node->v.element.children;
for (int i = 0; i < children->length; ++i)
{
res += find_definitions(static_cast<GumboNode *>(children->data[i]));
}
return res;
}
Далее, функция extract_text ниже извлекает текст из каждого узла, который не является тегом script или style. Функция направляет текст на процедуру str_replace, которая заменяет ведущее двоеточие на бинарный символ >.
std::string extract_text(GumboNode *node)
{
if (node->type == GUMBO_NODE_TEXT)
{
return std::string(node->v.text.text);
}
else if (node->type == GUMBO_NODE_ELEMENT &&
node->v.element.tag != GUMBO_TAG_SCRIPT &&
node->v.element.tag != GUMBO_TAG_STYLE)
{
std::string contents = "";
GumboVector *children = &node->v.element.children;
for (unsigned int i = 0; i < children->length; ++i)
{
std::string text = extract_text((GumboNode *)children->data[i]);
if (i != 0 && !text.empty())
{
contents.append("");
}
contents.append(str_replace(":", ">", text));
}
return contents;
}
else
{
return "";
}
}
Функция str_replace (вдохновленная одноименной функцией PHP) заменяет каждый экземпляр заданной строки поиска в большей строке на другую строку. Она выглядит следующим образом:
std::string str_replace(std::string search, std::string replace, std::string &subject)
{
size_t count;
for (std::string::size_type pos{};
subject.npos != (pos = subject.find(search.data(), pos, search.length()));
pos += replace.length(), ++count)
{
subject.replace(pos, search.length(), replace.data(), replace.length());
}
return subject;
}
Поскольку обход и замена в приведенной выше функции зависят от примитивов, определенных в библиотеке алгоритмов, вам также потребуется включить эту библиотеку:
#include ”algorithm”
Далее вы добавите динамическость в скрейпер, позволяя ему возвращать определения для каждого слова, переданного в качестве аргумента командной строки. Для этого вы определите функцию, которая преобразует каждый аргумент командной строки в его эквивалент в нижнем регистре, что минимизирует возможность ошибок запросов из-за перенаправлений и ограничивает ввод до одного аргумента командной строки.
Добавьте функцию, которая преобразует входные строки в их эквиваленты в нижнем регистре:
std::string strtolower(std::string str)
{
std::transform(str.begin(), str.end(), str.begin(), ::tolower);
return str;
}
Далее следует логика ветвления, которая выборочно анализирует один аргумент командной строки:
if (argc != 2)
{
std::cout << "Please provide a valid English word" << std::endl;
exit(EXIT_FAILURE);
}
Основная функция в вашем скрапере должна выглядеть так, как показано ниже:
int main(int argc, char **argv)
{
if (argc != 2)
{
std::cout << "Please provide a valid English word" << std::endl;
exit(EXIT_FAILURE);
}
std::string arg = argv[1];
std::string res = request(arg);
std::cout << scrape(res) << std::endl;
return EXIT_SUCCESS;
}
Вы должны включить библиотеку iostream C++, чтобы гарантировать, что примитивы ввода/вывода (IO), определенные в функции main, работают ожидаемым образом:
#include “iostream”
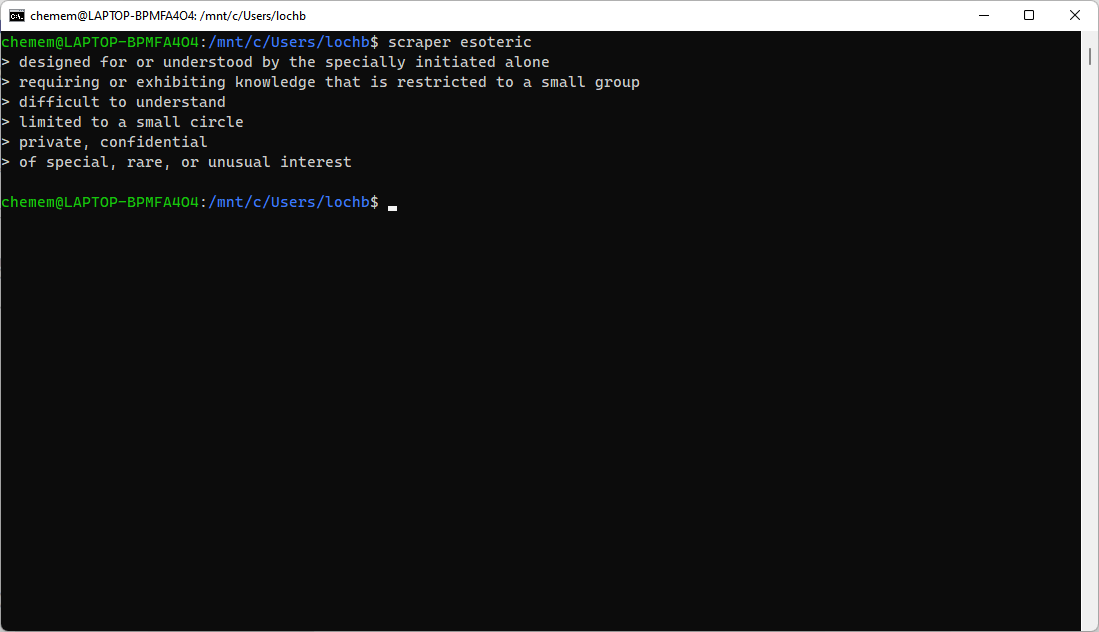
Чтобы запустить ваш скрапер, скомпилируйте его с помощью g++. Введите в консоль следующий текст, чтобы скомпилировать и запустить ваш скрапер. Он должен извлечь шесть перечисленных определений слова «эзотерика»:
$ g++ scraper.cc -lcurl -lgumbo -std=c++11 -o scraper $ ./scraper esoteric
Вы должны увидеть следующее:
Заключение
Как вы увидели в этой статье, C++, который обычно используется для системного программирования, также хорошо подходит для веб-скрапинга благодаря своей способности анализировать HTTP. Эта дополнительная функциональность может помочь расширить ваши знания в C++.
Обратите внимание, что этот пример был относительно простым и не рассматривал, как будет работать скрапинг для сайта с более сложной JavaScript-кодом, например, использующего Selenium. Чтобы выполнять скрапинг на сайте с более динамической отрисовкой, можно использовать безголовый браузер с библиотекой C++ для Selenium. Эта тема будет рассмотрена в будущей статье.
Чтобы проверить свою работу по этой статье, обратитесь к GitHub gist.
Ранее мы уже писали Что такое веб-скрапинг: Руководство для начинающих











 на 100 слоях")






