Как мы оптимизировали деплой и льем код в любое время суток
В статье я поделюсь нашим опытом и расскажу о том, как мы перестраивали процессы, стремясь к удобному и качественному деплою. Когда-то давно СТО (раньше эту должность занимал нынешний CEO Родион Ерошек) заходил на единственный сервер и вручную делал git pull origin master. Сейчас же наш серверный парк перевалил за 100, причем любой программист, прошедший испытательный срок, может задеплоить свой код на продакшен в любое время дня и ночи, и даже CTO обязан прислать соответствующей гильдии код на ревью перед деплоем на первых клиентов.
Статья будет интересна разработчикам и девопсам, которые ищут простые и удобные способы оптимизировать деплой.
Немного контекста
Poster — это высоконагруженный продукт: с помощью системы ежемесячно пробивается 17 млн чеков в 11 тыс. ресторанах в 90 странах мира. Система состоит из POS-терминала для официантов и админпанели для владельцев. Программа работает на iPad- и Android-планшетах, desktop-версии запускаются под Windows и macOS, есть и веб-версия.
Ядро системы работает на JS + PHP. Нативные приложения используют Objective-C и Swift, Java и Kotlin, Electron и React Native. Часть микросервисов написаны на Python и Node.js. Вся инфраструктура размещается примерно на 75 dedicated и 25 виртуальных и cloud-серверах. В Dev-команде 40 человек.
Система позволяет сторонним разработчикам интегрироваться с ней на четырех уровнях:
- API с веб-хуками;
- кастомные страницы в админпанели;
- отдельные JS-приложения, внедренные в POS-терминал и перехватывающие различные события;
- другие iOS- и Android-приложения на иных планшетах, взаимодействующие c POS-терминалом внутри локальной сети по отдельному протоколу.
Сегодня в маркетплейсе находится порядка 40 сторонних приложений, плюс еще примерно 400 закрытых личных интеграций.
Техническая автоматизация деплоя
Кажется, что это самая простая часть. Ведь мы же с вами программисты, а тут надо просто сесть и автоматизировать. Но как, с одной стороны, достичь идеального баланса и не оверинженирить, а с другой — постоянно поддерживать автоматизацию на должном уровне?
Мой совет: нужно постоянно следить за оверинжинирингом и точечно «накрывать огнем очаги сопротивления». Именно стремление к простым, удобным решениям и минимальному оверинжинирингу позволяет компаниям быстро расти. Программисты и другие сотрудники должны так расходовать свое рабочее время, чтобы компания получала от этого максимальную пользу.
Например, раньше мы сознательно не писали тесты, а максимально работали над новыми функциями системы, чтобы успеть закрепиться на растущем рынке. В тот момент с тестами работала только команда, отвечающая за передачу данных о продажах в налоговую (здесь цена ошибки была очень велика и измерялась штрафами наших клиентов).
Сейчас же тесты стали стандартом и входят в Definition of Done практически во всех командах. Хотя мы все еще против бездумного покрытия тестами ради самих тестов.
С автоматизацией деплоя происходило примерно то же самое. Мы проводили ее понемногу, маленькими шажками, когда уже упирались в ежедневную рутину ручного труда.
Ручной деплой
В первый год жизни компании, когда в ней работало лишь несколько программистов, CTO выливал код банальным git pull origin master. Этого было достаточно, ведь деплой чего-то нового происходил не каждый день.
Первой ласточкой стала автоматизация миграций. Данные каждого клиента Poster хранятся в отдельной базе. В первый год работы компании, чтобы провести миграцию баз, программисты писали новый метод в контроллере 🙂 Затем происходило переподключение по всем базам и выполнение какого-то SQL-ника или куска PHP-кода. А передача изменений между разработчиками, которым также надо было локально обновить у себя базу, осуществлялась через Skype.
Эта схема накрылась примерно тогда, когда я пришел в компанию. Кто-то забыл скинуть в Skype один из SQL-запросов, и после деплоя система начала работать совсем не так, как надо. Я выбил неделю для устранения этой проблемы и написал библиотеку, которая могла бы гибко мигрировать все базы клиентов или какую-то конкретную.
В то время миграция была одной из нескольких задач, которые я каждый раз выполнял при деплое. Со временем туда добавились задачи по сборке и подготовке CSS- и JS-файлов, и время деплоя существенно увеличилось. При этом надо было постоянно следить за процессом и выполнять следующие команды лишь после успешного завершения предыдущих. Это было долго и неэффективно. Наконец мы решили полноценно автоматизировать сборку. После недолгого поиска среди простых решений выбор пал на Capistrano.
Capistrano
С Capistrano мы прожили около года. Постепенно добавляли туда все больше команд, и время деплоя снова увеличилось. Архитектура Capistrano не позволяла нам гибко ускорять процесс. К тому же, чтобы повысить отказоустойчивость, мы созрели к канареечному деплою. В итоге начали искать альтернативу и перешли на Deployer.
Deployer
Мы до сих пор используем эту библиотеку для билда и доставки кода на боевые серверы. Нам удалось разбить процесс билда на подзадачи и проводить миграции лишь тогда, когда это действительно нужно. Сборка и компиляция происходят только в том случае, если в файлах были изменения.
Со временем мы начали использовать параллельный деплой на все app-серверы одновременно. Это позволяет выливать новый код на десятки серверов в среднем за 5-7 минут. Конечно, бывает и дольше, особенно если есть миграции или же в коде было очень много изменений (но теперь это мало кого беспокоит, так как все выполняется уже без участия разработчиков).
/*
* Deploy task
*/
task('deploy', [
'deploy:info',
'deploy:lock',
'deploy:prepare',
'deploy:release',
'deploy:update_code',
'deploy:last_commit',
'deploy:copy_dirs',
'deploy:copy_files',
'deploy:npm_install',
'deploy:build',
'deploy:shared',
'deploy:shared_local',
'deploy:check_migrate_pos',
'deploy:check_migrate',
'deploy:symlink_previous',
'deploy:appcache_generate_data',
'deploy:prepare_migrate',
'deploy:symlink',
'deploy:generate_webp',
'deploy:reset_opcache',
'deploy:migrate_pos',
'deploy:migrate',
'deploy:update_appcache',
'cleanup',
'deploy:unlock',
]);
После перехода на Deployer мы деплоили примерно два года с локальных машин. На тот момент у нас толком не было тестов, поэтому такой процесс нас хоть и с натяжкой, но устраивал. Когда же мы наняли первого Automation QA, то вариантов не создавать полноценный CI-/CD-процесс уже не было. У нас появился выделенный DevOps-инженер, который этим и занялся.
GitLab
CI-/CD-процесс мы организовали в рамках своего GitLab-сервера. Сначала создали pipeline для прохождения тестов, а после этого добавили отдельный pipeline непосредственно для деплоя после принятия MR.
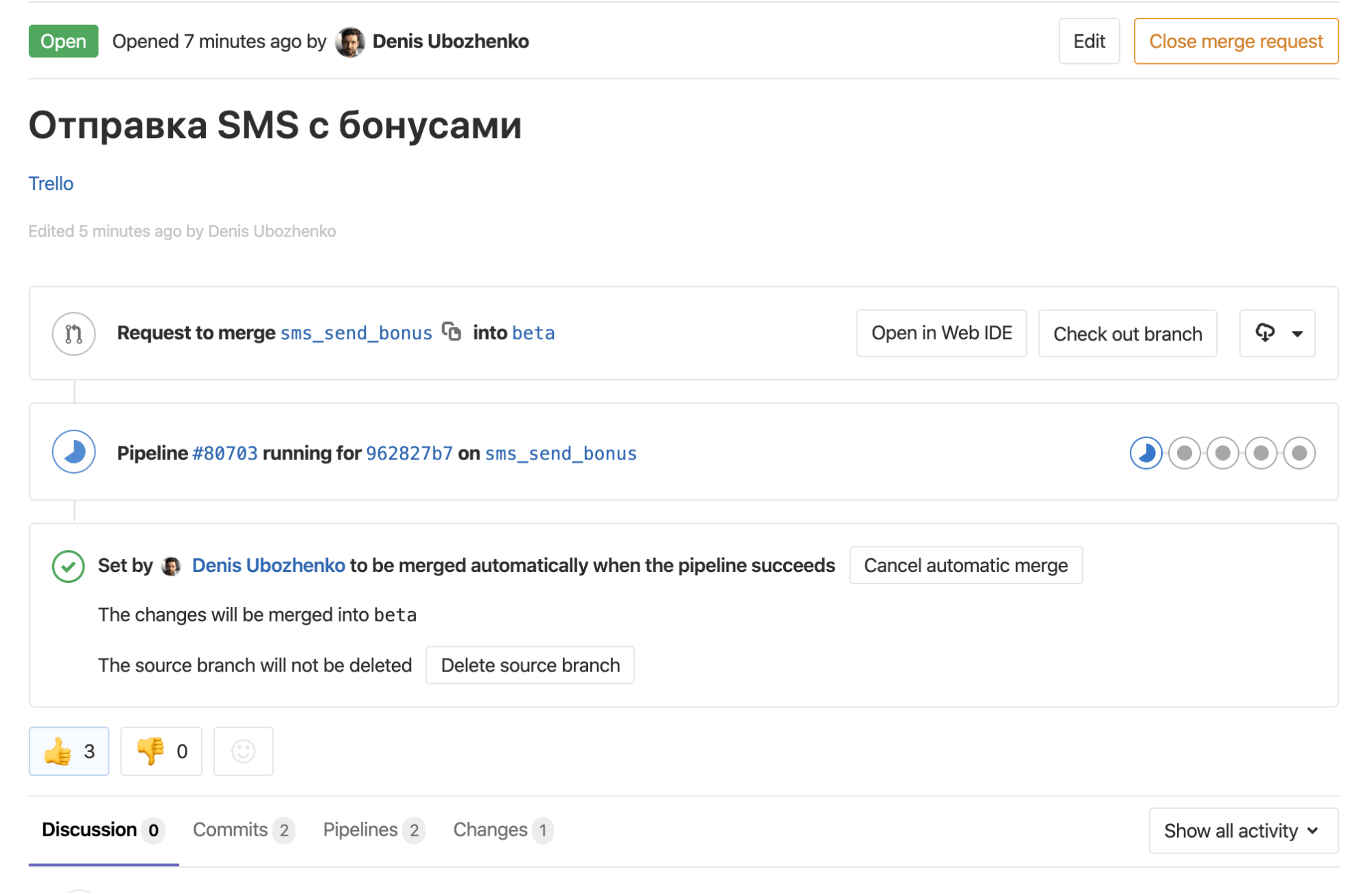
В итоге сейчас все, что нам надо сделать, чтобы вылить какую-то ветку, это поставить MR в GitLab, а затем принять его после прохождения тестов. Либо же сразу выбрать автоматический деплой после прохождения тестов. И все.
4 часа, die(); и 11 514 чеков
Однажды года четыре назад я деплоил ночью большое изменение, которое нельзя было выливать днем: задача требовала вынужденной блокировки аккаунтов для проведения сложных миграций в базах. Хоть я и проверил, чтобы POS-терминалы клиентов запускались, но в сонном состоянии не учел, что это был кеш, который позволяет нашим клиентам работать offline. Довольный результатом работы я пошел спать. А в это время система лежала четыре часа. Тогда у нас еще не было круглосуточной технической поддержки, и до утра меня никто не разбудил… До сих пор с ужасом вспоминаю то утро.
Три года назад после окончания отлова одной из ошибок разработчик забыл <? die();?> в библиотеке, отвечающей за синхронизацию POS-терминалов с бэкендом. Благодаря дикой случайности этот код не ушел на серверы и не поломал нашим клиентам синхронизацию.
В тот же год наш будущий DevOps-инженер вылил код, который за 20 минут поломал закрытие 11 514 чеков. Мы потратили 12 часов, чтобы достать детали клиентских данных из логов и починить их.
К счастью, такие случаи были единичными, но именно благодаря им у нас появились E2E-тесты, а затем API- и unit-тесты. Только пройдя через боль и страдания, бизнес принимает необходимость автоматического тестирования.
Но если быть честным, хотя pipeline c автоматическим прохождением тестов появился у нас полтора года назад, к тому времени мы уже лили код по пятницам и выходным. Причиной этого была культура тестирования, которой мы придерживались давно. Задолго до этого нам пришлось также внедрить ряд инструментов, чтобы автотестирование стало реальностью.
Клонирование баз
Первое, что мы сделали, это автоматизировали клонирование баз с боевых серверов на локальные машины разработчиков. Сначала это был один маленький bash-скрипт, затем второй, третий и так далее, пока все скрипты не превратились в библиотеку poster-core-tools. Сейчас любой разработчик может законтрибутить туда изменение, которое автоматизирует его работу или работу всего отдела. Клонирование баз привело к тому, что мы смогли локально тестировать написанный нами код на данных лояльных клиентов.
QA-инженер
Мы очень долго сопротивлялись появлению у нас QA-инженеров. Как и у многих продуктовых компаний, у нас был стереотип, что разработчики должны писать код, не требующий дополнительного тестирования. И долгое время мы работали именно так: все разработчики тестировали свой код самостоятельно, либо это делали техлиды во время ревью.
Но с ростом команды мы пришли к пониманию, что наличие QA не тормозит процесс, а только ускоряет его. В конце третьего года работы компании мы наняли QA-инженера и ни разу об этом не пожалели. Опытные QA знают всю систему и хорошо отслеживают регрессию кода. Особенно это помогает, когда к команде присоединяются новые разработчики.
Stage-сервер
Мы создали свой первый stage-сервер, куда научились выливать любую ветку с любой базой для проверки нового кода. Stage-сервер стал настолько популярным, что нам практически сразу пришлось добавить еще несколько: команда технической поддержки захотела делать то же самое во время обработки клиентских тикетов, чтобы удостовериться в наличии бага.
Когда запросы на stage-серверы превысили десять штук, в poster-core-tools была добавлена возможность разворачивать их автоматически. Сейчас у нас 40 серверов для ручного тестирования и еще 10 для прогона автоматических тестов. При необходимости можем добавить еще пару десятков запуском одной утилиты.
AQA-инженер
Два года назад мы наняли первого AQA-инженера. Нам понадобилось примерно 8 месяцев, чтобы покрыть все основные функции E2E-тестами и создать свой первый pipeline для проверки работоспособности системы.
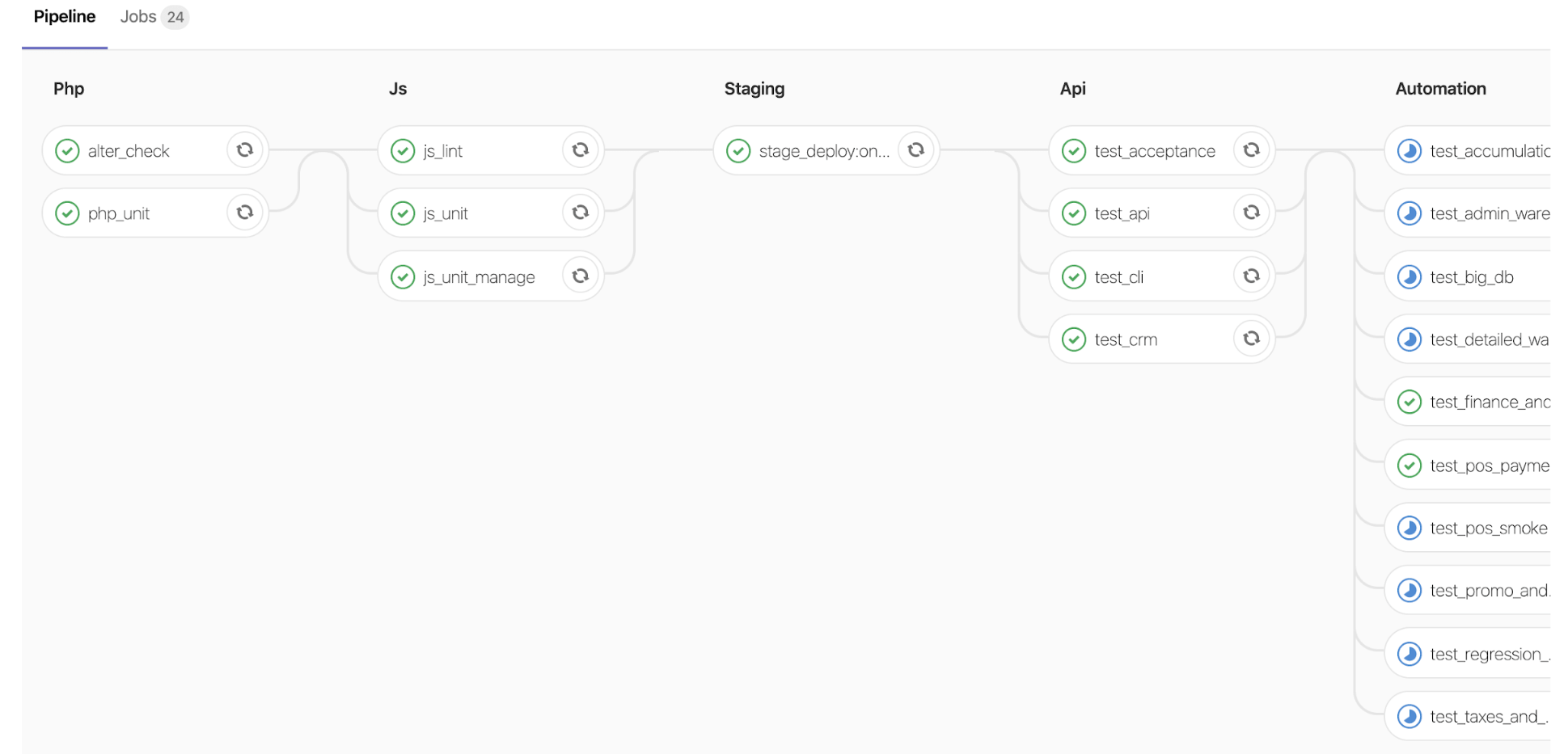
Параллельно с E2E-тестами мы начали писать API-тесты и развивать культуру написания unit-тестов. Нельзя сказать, что все идет гладко, но практически ежеквартально у нас происходят какие-то изменения в процессе тестирования.
Примером такого изменения стало появление QA-гильдии. QA-инженеры изо всех команд собираются раз в спринт, обсуждают то, что было сделано за последние две недели, составляют план написания тест-кейсов на следующий спринт, а также синхронизируются с AQA-инженером.
Канареечный деплой
Отдельно хочу рассказать о канареечном деплое. Мы ввели его четыре года назад, чтобы максимально быстро доставлять пользователям изменения продукта. Такие пререлизы позволяют безопасно тестировать новые функции на небольшом проценте пользователей. А если с обновлением что-то идет не так, можем быстро откатиться назад, и большинство клиентов ничего не заметит.
Сначала такой деплой состоял из beta- и production-веток. Со временем к ним добавились testing, а примерно год назад stable-ветки. В итоге сейчас у нас следующая схема разлива кода:
Beta 5% → Testing 10% → Production 15% → Stable 70%
Все разработчики ежедневно льют свой код в beta, на следующий день он переливается из beta в testing, а еще через день — из testing в production. Каждый понедельник код меняет распложение — из production в stable.
Клиенты находятся в постоянной ротации между ветками согласно простому алгоритму: остатку от деления их ID на 5. При этом на ветки ниже stable стараемся переносить клиентов с наибольшим ID, чтобы «старики» оставались на stable. На beta находится примерно 5% клиентов с остатком, равным 1; на testing — 10% с остатком, равным 2; на production — 15% с остатком, равным 3; а все остальные — на stable.
У нас есть еще три ветки — beta 2, beta 3 и beta 4. На них выливаются большие или сложные изменения, которые требуют неопределенного времени тестирования в боевых условиях на работающих лояльных клиентах. После этого код переносится в стандартную beta-ветку.
Доверяй, но проверяй
Сейчас каждый разработчик, прошедший испытательный срок, получает право деплоя на боевые серверы. Но так было не всегда.
В самом начале код на боевые серверы выливали основатели компании. Ревью проходило по-разному: где-то код проверялся внимательно, а где-то — по диагонали.
Когда тогдашнему CTO надоело смотреть мой код и мы научились деплоить с помощью Capistrano, все ревью кода и право деплоя негласно перешли ко мне. Так продолжалось примерно полтора года, пока я не стал самым узким местом в ядре и из-за меня не начала падать скорость доставки фич клиентам.
Это был первый урок: мы поняли, что техлид не должен тормозить и надо делегировать право деплоя и ревью другим ребятам. В тот момент я уже занимал позицию CTO, и надо было как-то ускорять процесс. Таким ускорением и стало появление позиций техлидов среди бэкенд- и фронтенд-разработчиков. Эти ребята взяли на себя обязанности ревью и деплоя, что существенно продвинуло нас вперед.
Постепенно мы реорганизовали команды в кросс-функциональные и выделили в каждой из них по два бэкенд- и одному фронтенд-техлиду, чтобы они могли ревьюить и деплоить код других ребят. Сначала все было хорошо, но со временем стало выглядеть дико: трое из шести разработчиков занимали позиции техлидов, которые преимущественно отвечали за ревью и деплой.
Такая система просуществовала примерно полтора года, пока в одной команде по ряду причин не остался один бэкенд-техлид на трех бэкенд-разработчиков. Проводя все время за ревью и деплоем, он начал слегка зашиваться.
Весной прошлого года мы приняли сложное, но революционное на тот момент решение: упразднили позиции техлидов и дали право на деплой всем, кто прошел трехмесячный испытательный срок. Благо тогда в командах уже сформировалась культура кросс-ревью, и такая реорганизация прошла безболезненно. Плюсом стало еще и то, что ответственность за вылитый код переместилась с техлида на автора кода.
Сейчас уже видно, что мы приняли правильное решение. К сожалению, в настоящее время ревью кода не такое плотное, как было ранее. И в первую очередь это касается тех ребят, которые одиночки по своей технологии в командах. Эту проблему решаем гильдиями, но, думаю, в ближайшие полгода процесс ревью для них изменится в лучшую сторону.
Примерно три месяца назад на собрании Dev-отдела, я, CEO и Head of Engineering получили запрет на деплой кода без ревью соответствующей гильдии… Так и живем, создавая отдел по бирюзовой методологии.
Подведем итог
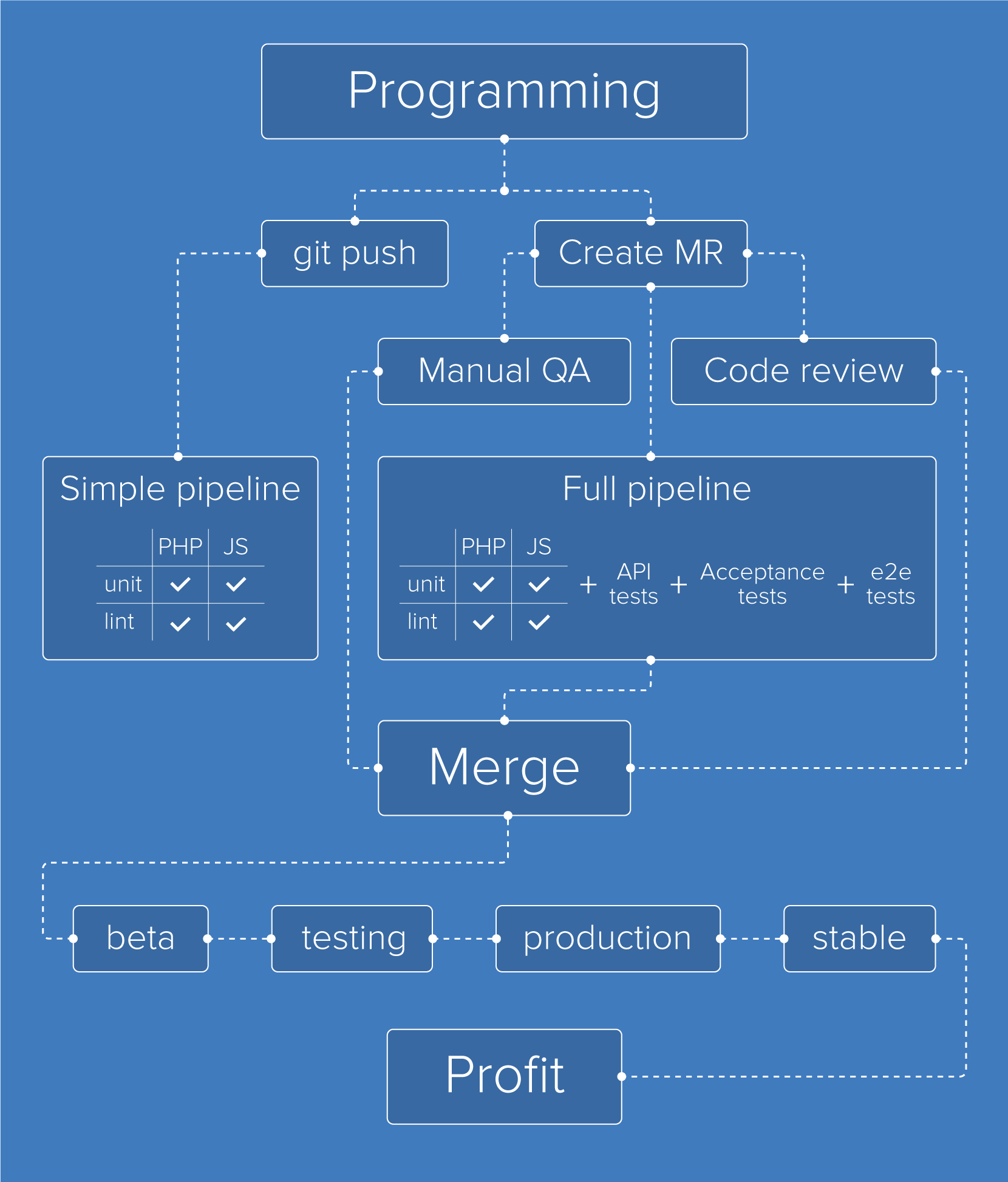
Сейчас из инструментов мы используем GitLab (для хранения репозитория) и Continuous Integration. Для Continuous Deployment применяем Deployer, а стартует все также из GitLab.
Каждый раз, когда разработчик пушит свой код в репозиторий, мы прогоняем unit-тесты и проверяем code style для JS и PHP.
После того как ветка готова, разработчик ставит MR. В этот момент запускается расширенный pipeline вместе с деплоем ветки на stage-серверы, зарезервированные под автотесты. В качестве тестов сейчас гоняем API-тесты, приемочные на Codeception и E2E-тесты на Selenium.
Далее порядок работы уже по желанию разработчика: ждет он прохождения автотестов или нет, но должен отдать ветку на ревью и, возможно, на мануальное тестирование. Для проведения мануального тестирования QA-инженеры выливают код на stage-серверы и прогоняют там свои тест-кейсы.
Как только все виды тестов и ревью пройдены, в GitLab принимается MR и код автоматически выливается на клиентов, находящихся на beta-ветке. На следующий день код будет перемещен на testing, а затем на production. С наступлением ближайшего понедельника код из production попадет на stable.
При необходимости разработчик может вылить код не на beta, а на beta 2 / beta 3 / beta 4 и перевести туда нескольких заинтересованных клиентов, чтобы они какое-то время потестили фичу. Но потом она все равно будет влита в beta.
Что дальше
Несмотря на все, мы видим в нашей системе деплоя еще уйму возможностей для улучшения и в ближайшем будущем планируем ее модифицировать. Вот только часть плана:
- Добавить в pipeline SonarQube, чтобы ускорить и упростить дальнейшее ревью кода.
- Сделать автоматический, а не ручной ежедневный перелив кода между ветками beta ⟶ testing ⟶ production ⟶ stable в рамках канареечного деплоя. Сейчас MR создаются автоматически, но после прохождения всех тестов подтверждаются вручную.
- Улучшить алгоритм и автоматизировать выбор клиентов для канареечного деплоя. Уйти от «глупого» остатка от деления и начать использовать более качественное распределение. Например, чтобы на beta, testing и production были клиенты как с большим, так и маленьким количеством чеков, с большим и маленьким меню, клиенты, работающие со всеми типами оборудования, и так далее. Это позволит находить неточности в новом коде раньше, не дожидаясь их попадания на всех клиентов.
- Деплоить только после получения определенного количества лайков со стороны гильдии.
- Автоматизировать выбор тех, кто будет ревьюить код.
И наконец, мы созрели для полного переосмысления своего текущего подхода к CI/CD, чтобы его можно было масштабировать с основного проекта на сателлитные подпроекты и микросервисы. Пока большая часть из них по-прежнему деплоится вручную без своих pipeline. Этим мы и займемся в скором времени.











 на 100 слоях")





