В этой статье речь пойдёт об Apache Kafka и том, как этот продукт используется для обеспечения потребностей команд разработки. Статья не погружает в технические аспекты, но может быть полезна архитекторам и менеджерам, которые думают о том, чтобы попробовать использовать Kafka, но не знают, подойдёт ли она для их задач, а также разработчикам, которые могут открыть для себя новые инструменты для удобной работы с кластерами.
На момент написания статьи силами нашей команды развёрнуты и поддерживаются 14 продуктивных кластеров (1 централизованный и 13 у продуктовых команд) и 15 непродуктивных.
Централизованный кластер Kafka
Основной сценарий, в рамках которого Kafka использует наша команда – доставка логов в Elasticsearch.
Немного цифр об этом кластере для начала:
- брокеры — 5
- топики – 179
- consumer группы – 77
- средний объем данных[1] в топиках – 555.1 ГБ
[1] значение за последние 90 дней
Небольшое лирическое отступление. Многие сталкивались с ситуацией, когда в одно прекрасное утро ты видишь на графиках резкий рост количества логов, но не понимаешь, что именно стало причиной: новые команды не заезжали в сервис, новый функционал не планировался, и команды не предупреждали о том, что ожидается рост (потому что изначально команда закладывает вычислительные мощности под определенный объем данных). В результате расследования выясняется, что разработчики просто включили уровень логирования Debug или Trace. Также, иногда, встречаются сложные системы, бизнес-логика которых требует сохранять максимально полную информацию, растущая, как снежный ком, с течением времени. Например, X5 использует в работе систему маркировки табачных изделий. В какой-то момент мы обнаружили, что размер одного сообщения с логами достигает порядка 600 кб, потому что вся информация о продукции и ее перемещении дополняется на всем пути до магазина.
Поэтому для нас также было важно обеспечить доступность сервиса и не позволить, чтобы поток логов перегрузил нашу систему до отказа в результате незапланированного роста количества данных.
На этапе проектирования сервиса сбора логов, команда поняла, что необходимо гарантировать запись в Elasticsearch всех без исключения событий. Таким образом обеспечивается целостность данных, которые поступают от внешних систем, и команды всегда могут получить полную картину в том виде, в котором они пришли из внешних источников. Помимо этого, важно было иметь в виду, что количество команд будет расти со временем, а сервисы развиваться. Количество сообщений и информации в них будет увеличиваться, а для нас будет более затруднительно контролировать, какую информацию в логах пишут команды. Это значит, что мы должны сделать отказоустойчивую систему, которую можно сравнительно легко масштабировать в будущем.
Для достижения этих целей нам отлично подошло решение Apache Kafka по следующим причинам:
- репликация и валидация записи. Kafka имеет механизм валидации записи – acknowledgements. С помощью параметра acks можно настроить, сколько брокеров (реплик) должны отправить на producer подтверждение записи. Конечно, использование acks, особенно в случае, если мы хотим быть уверены, что данные реплицировались на все брокеры, добавляет небольшую задержку, которая требуется на репликацию. Но для нас важнее быть уверенными, что данные, которые мы хотим передавать дальше, будут записаны в Kafka;
- хранение сообщений в очереди. Если потребитель (в нашем случае это Logstash, который забирает сообщения из Kafka) по какой-то причине не успевает обрабатывать сообщения или просто недоступен, эти данные будут прочитаны и доставлены в конечную систему сразу после стабилизации работы потребителей;
- хранение сообщений после прочтения. Kafka не удаляет сообщения, а хранит в течение времени, которое описывается в параметрах retention. Это дает возможность восстановить данные в случае, если что-то случится с индексом в Elasticsearch и данные станут недоступны;
- партиционирование.За счет увеличения числа партиций топика можно увеличить пропускную способность Kafka, добавив дополнительных потребителей. Это увеличивает количество потоков, которые могут читать данные параллель и полезно в случае, когда producer генерирует большое количество сообщений.
Изначально кластер был развернут на трех машинах, но после роста числа команд мы масштабировали кластер, добавив ещё две ноды.
| # | vCPU | RAM | Storage[2] | Kafka | Kafka Uptime | Zookeeper | ZK Uptime |
| 1 | 4 | 16 ГБ | 290 ГБ | + | 1г1м | + | 1г5м |
| 2 | 4 | 16 ГБ | 270 ГБ | + | 1г1м | + | 1г5м |
| 3 | 4 | 16 ГБ | 290 ГБ | + | 1г1м | + | 1г5м |
| 4 | 4 | 16 ГБ | 270 ГБ | + | 4м | — | — |
| 5 | 4 | 16 ГБ | 270 ГБ | + | 1г1м | — | — |
[2] – учитывается объем, отведенный под данные Kafka
Мы видим, что последние 2 ноды были добавлены в кластер чуть более года назад, как раз в это время и произошел перезапуск сервиса на нодах 1-3, а на 4-й ноде перезапуск происходил позднее, скорее всего, проводились какие-то работы.
Когда внутри одной системы хранятся данные нескольких команд важно обеспечить конфиденциальность данных и разграничить права доступа.
Управление доступами
Чтобы разграничить команды по топикам, мы используем Kafka Security Manager. Все правила доступа мы описываем в файле с ACL. Выглядит это вот так:
User:projectprodwrite@srelogs,Topic,PREFIXED,projectprod,Create,Allow,
User:projectprodread@srelogs,Topic,PREFIXED,projectprod,Read,Allow,
User:projectprodread@srelogs,Group,PREFIXED,projectprod,All,Allow,где:
User – CN сертификата, который используется для подключения,
srelogs – имя кластера,
Topic/Group – объект, которым управляет данная запись,
PREFIXED/LITERAL – как будет применяться, относительно именем объекта в Kafka (по префиксу или полное совпадение),
project_prod – имя объекта и права, которые получает пользователь.
Producer/consumer авторизуются с помощью SSL сертификатов, которые мы генерируем автоматически и храним в Vault.
Интеграция в конвейер поставки логов
Подготовка всех необходимых компонентов выполняется с помощью ролей Ansible. В зависимости от окружения (продуктивное или непродуктивное), и прочих параметров, описанных в инвентаре, создается набор сущностей и конфигурируются нужные сервисы (индексы и тенанты в Elasticsearch, пайплайны в Logstash)
После того, как все необходимые компоненты созданы и настроены, топики автоматически создаются, как только первые сообщения начинают отправляться в Kafka благодаря параметру auto.create.topics.enable=True
Для обеспечения высокой производительности кластера, рекомендуется использовать Kafka с сообщениями небольшого размера. По этой причине мы настоятельно рекомендуем командам следить за тем, чтобы в логи писалась только полезная информация, а для Elasticsearch поставили ограничение на размер одного сообщения.
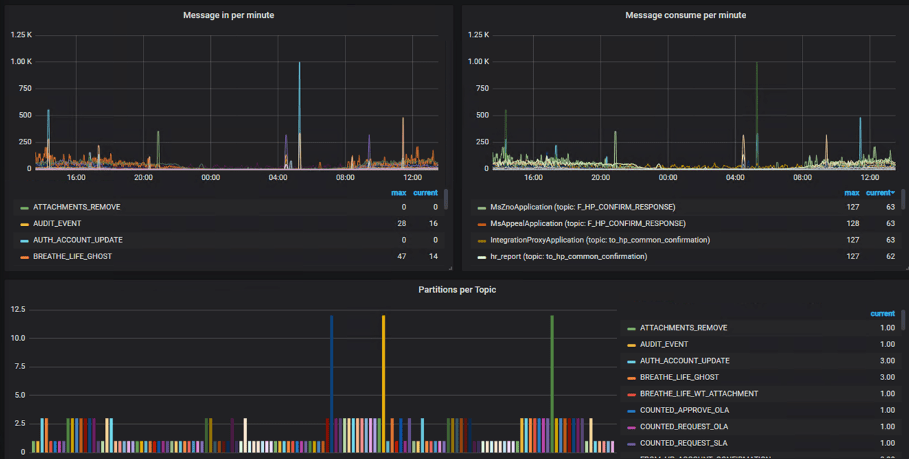
В целом, графики измеряющие поток входящих сообщений показывают нам стабильную и равномерную картину, однако, время от времени возникают неожиданные всплески (фиолетовые и желтые графики), которые создают команды разработки в топиках dev сред, предположительно, во время проведения тестов.
Использование Kafka в цепочке поставки логов позволяет нам контролировать поток входящих сообщений, Logstash (у каждой команды свой) будет равномерно вычитывать все, что попадает в топик Kafka, а мы будем спокойны, что наш конвейер поставки логов не упадет от внезапно возросшей нагрузки. В случае, если наш consumer станет недоступен или не будет справляться с нагрузкой, все события так или иначе останутся в топике и будут прочитаны и отправлены в Elasticsearch после восстановления работоспособности Logstash.
Кластер для команды
Кроме большого кластера, который мы используем для гарантированной доставки логов, некоторые команды используют кластеры Kafka в своих проектах. При этом задачи, которые они решают с помощью этого продукта, схожи с нашими – гарантированная запись данных, возможность обратиться к любым данным в течение времени их жизни в топике, отказоустойчивость и целостность.
У нас есть информационный ресурс, в котором описаны все сервисы, предоставляемые нашей командой, в том числе и параметры по умолчанию, которые устанавливаются для той или иной системы. Аналогичные «дефолтные» значения прописаны и для кластера Kafka. Вот некоторые из них:
auto.create.topics.enable=True
delete.topic.enable=True
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connection.timeout.ms=6000
auto.leader.rebalance.enable=trueНести в статью все, что описано в ролях Ansible я не вижу смысла, но приведу некоторые примеры того, что используем мы в X5 .
Для обеспечения надежности кластера рекомендуется использовать количество реплик равное количеству нод и выставить значение минимально синхронизированных реплик на единицу меньше, чтобы в случае вылета одного узла, кластер смог продолжить работу. Для удобства мы используем именно эти значения, если иное не описано в инвентаре для проекта:
- name: 01|Set Kafka replication factor
set_fact:
kafka_cfg_default_replication_factor: "{{ kafka_cfg_default_replication_factor | default(kafka_hosts|length) }}"
kafka_cfg_offsets_topic_replication_factor: "{{ kafka_cfg_offsets_topic_replication_factor | default(kafka_hosts|length) }}"
kafka_cfg_transaction_state_log_replication_factor: "{{ kafka_cfg_transaction_state_log_replication_factor | default(kafka_hosts|length) }}"
run_once: True
- name: 01|Set kafka ISR
set_fact:
kafka_cfg_min_insync_replicas: "{{ kafka_cfg_min_insync_replicas | default([kafka_cfg_default_replication_factor|int - 1 , 1] | max) }}"
kafka_cfg_transaction_state_log_min_isr: "{{ kafka_cfg_transaction_state_log_min_isr | default([kafka_cfg_transaction_state_log_replication_factor|int - 1 , 1] | max) }}"
run_once: True
По умолчанию мы выставляем удаление всех событий старше 30 дней, обычно этого хватает командам:
log.retention.hours=720В случае, если команде требуются иные значения, то изменить какие-то параметры несложно. Нужно просто описать параметры и их значения в инвентаре нужного проекта:
Project.yml
---
project: name
. . .
kafka_scala_version: "2.11"
kafka_zk_chroot: '/'
kafka_enable_protocol: ['PLAINTEXT']
kafka_cfg_default_replication_factor: 2
kafka_cfg_log_retention_hours: 6
kafka_cfg_log_segment_bytes: 52428800Как и в случае с общим кластером, для обеспечения безопасности, мы используем SSL сертификаты. По умолчанию предоставляем кластер с параметром kafkaenableprotocol: [‘SSL’], что гарантирует возможность подключения к кластеру только тех, кто имеет соответствующие клиентские сертификаты.
- name: Lookup for ssl data in Vault
set_fact:
jks_b64: "{{ lookup('hashi_vault', 'secret=sre/{{ env }}/{{ project }}/kafka/{{ inventory_hostname }}:kafka.keystore.jks.b64') }}"
- name: Copy keystore data from Vault
copy:
dest: "/opt/kafka/ssl/{{ inventory_hostname }}/kafka.keystore.jks"
content: "{{ jks_b64 | b64decode }}"Для удобства управления мы заворачиваем Kafka и Zookeeper в сервисы, поскольку не используем контейнеры. Пример шаблона сервиса Kafka, который Ansible приносит на виртуальную машину:
[Unit]
Description=Kafka Daemon
After=zookeeper.service
[Service]
Type=simple
User={{ kafka_user }}
Group={{ kafka_group }}
LimitNOFILE={{ kafka_nofiles_limit }}
Restart=on-failure
EnvironmentFile=/etc/default/kafka
ExecStart={{ kafka_bin_path }}/kafka-server-start.sh {{ kafka_config_path }}/server.properties
ExecStop={{ kafka_bin_path }}/kafka-server-stop.sh
WorkingDirectory={{ kafka_bin_path }}
[Install]
WantedBy=multi-user.targetПлюсы такого разделения:
- разграничение ресурсов. Каждая команда знает, сколько ресурсов выделено конкретно под их продукт, и не переживает о том, что проект-сосед может занять большой объем оперативной памяти, тем самым повлиять на производительность их системы. Помимо этого, мы можем предоставлять командам разработки дополнительные инструменты и не думать о том, что какие-то из их действий могут навредить кому-то еще кроме них самих;
- гибкость управления.В случае, если необходимо изменить какие-то параметры и перезапустить Kafka, не требуется согласовывать работы с большим количеством команд.
Пример нагрузки на одном из кластеров, который использует система маркировки:
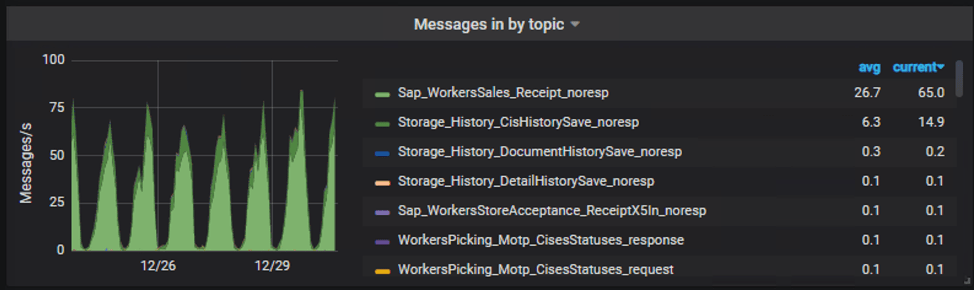
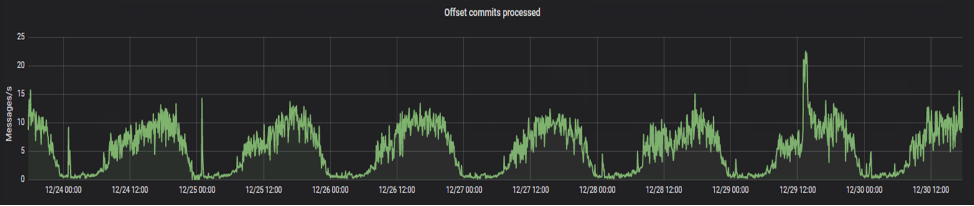
Видно, что нагрузка на систему держится примерно на одном уровне на протяжении любого периода времени (в примере это неделя).
Из минусов можно выделить то, что Kafka может быть избыточна для команд, которым нужен простой брокер сообщений.
Дополнительные инструменты для работы с Kafka
Поскольку основными пользователями отдельных кластеров являются продуктовые команды, мы должны обеспечить их всем необходимым для того, чтобы можно было следить за состоянием кластера, получать информацию о настройках и содержимом топиков.
Таким набором по умолчанию у нас являются экспортеры для сбора метрик и панели графиков Grafana для визуализации этих метрик:
jmx-exporter – позволяет отслеживать состояние Java Virtual Machine,
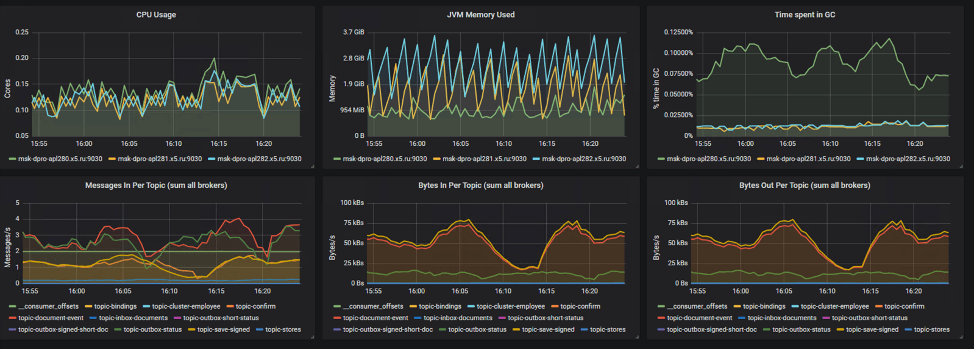
kafka-exporter, zookeeper-exporter – для того чтобы понимать, как себя чувствуют наши сервисы и получать поверхностную картину,
telegraf – дает информацию о состоянии ноды, на которой крутится Kafka.
Большинству команд этого хватает. Для тех, кому нужно чуть больше информативности, мы предлагаем kafka-minion exporter (https://github.com/cloudworkz/kafka-minion), который позволяет получать больше информации о том, что происходит с топиками, например, сколько групп потребителей подключены к топику и т.п.
Поскольку у команд нет прямого доступа на сервер с Kafka, им нужно дать возможность просматривать содержимое и, например, быстро удалять топики, не дергая для этого каждый раз нас. Для решения этих задач мы предлагаем использовать Kafdrop (https://github.com/obsidiandynamics/kafdrop). Для оперативного предоставления Kafdrop, мы используем готовый CI pipeline, который поднимает в окружении OpenShift два пода: Kafdrop и nginx. В результате мы получаем web UI с basic аутентификацией, настроенной средствами nginx.
Помимо этого, точечно по запросам команд мы можем подготовить различные коннекторы, например, коннекторы для баз данных (PostgreSQL Connector, MongoDB Kafka Connector), ksqlDB или Kafka REST Proxy для взаимодействия с кластером через REST API.
Заключение
Как видно из нашего рассказа, Kafka отлично зарекомендовала себя в качестве вспомогательного сервиса в цепочке поставки логов, в том числе за счет удобства масштабирования и возможности вернуться к сообщениям, которые уже были прочитаны. Для применения в разработке продуктов Kafka имеет всевозможные коннекторы, которые облегчают интеграцию с другими компонентами продукта. Кроме этого, существует большое количество инструментов, облегчающих жизнь инженеров и разработчиков, работающих с кластером.
Тем не менее, для команд не всегда этот инструмент подходит из-за возможной избыточности функционала и объема необходимых вычислительных ресурсов, что в свою очередь увеличивает затраты на бюджет проекта. Именно поэтому сейчас мы начинаем в пилотном режиме предоставлять командам RabbitMQ, но это уже совсем другая история.
Возможно вам будет интересно — Подборка программ — инструментов для системного администратора.







 на 100 слоях")




